
- Dec 3, 2024
- 8 minutes
Written By
As technology continually moves forward, companies need to keep their data infrastructure up to date with current standards. More traditional companies, in particular, have to ensure their enterprise resource planning (ERP) systems stay updated and maintained.
However, these systems can become obsolete. More importantly, larger companies often juggle different ERP systems, which can lead to several drawbacks, the most critical of which could be the loss of crucial data or workflow inefficiencies. PwC wrote an article on the benefits of having a consolidation system, and ABB published a case study on how unifying their 40 ERPs saved millions of dollars. Therefore, a unified company data architecture can mitigate the risks inherent to mixed ERP systems while bringing significant savings.
In this article, we will explore how we can use Palantir AIP as a data migration tool as the ERP consolidation engine and empower business to solve data quality issues.
Why use AIP as a Data Migration tool?
Palantir AIP is an end-to-end data platform that empowers both business users and developers to make data-driven decisions, enabling effective asset and risk management.
Typically, this involves the construction of ETL pipelines accompanied by the most useful aspect of the platform, the Ontology layer. In most use cases, once the data is cleaned and has been modelled into the Ontology layer, AIP users will create applications (e.g., using Workshop) such as a Supply Chain Control Tower or other analytics and operational dashboards.
In the context of a data migration workflow, the Ontology layer will not be used for the migration process itself but will be the foundation of our Data Quality enhancement framework. Let’s first focus on the three sections of ETL workflows.
Extract and Load
AIP provides the Data Connection application to bring data from external systems onto your stack. There are many out-of-the-box integrations available, such as AWS S3, SFTP, HDFS, etc., but it is also possible to establish custom connections to systems that don’t fit the currently available solutions.
Moreover, AIP also enables outbound data connections in order to write back processed data to external systems.
Transformation
Pipeline Builder is an application that enables developers to build production-grade data integration pipelines. What makes this application so powerful is its easy-to-learn features. Users can describe the transformations that their data should go through thanks to a wide array of transformation blocks, and the backend will then write the transform code and perform checks on the pipeline’s integrity.
For example, one common step in data cleaning is the trimming of strings. This can easily be done in a pipeline by looking for the “Clean string” transformation and then applying it.
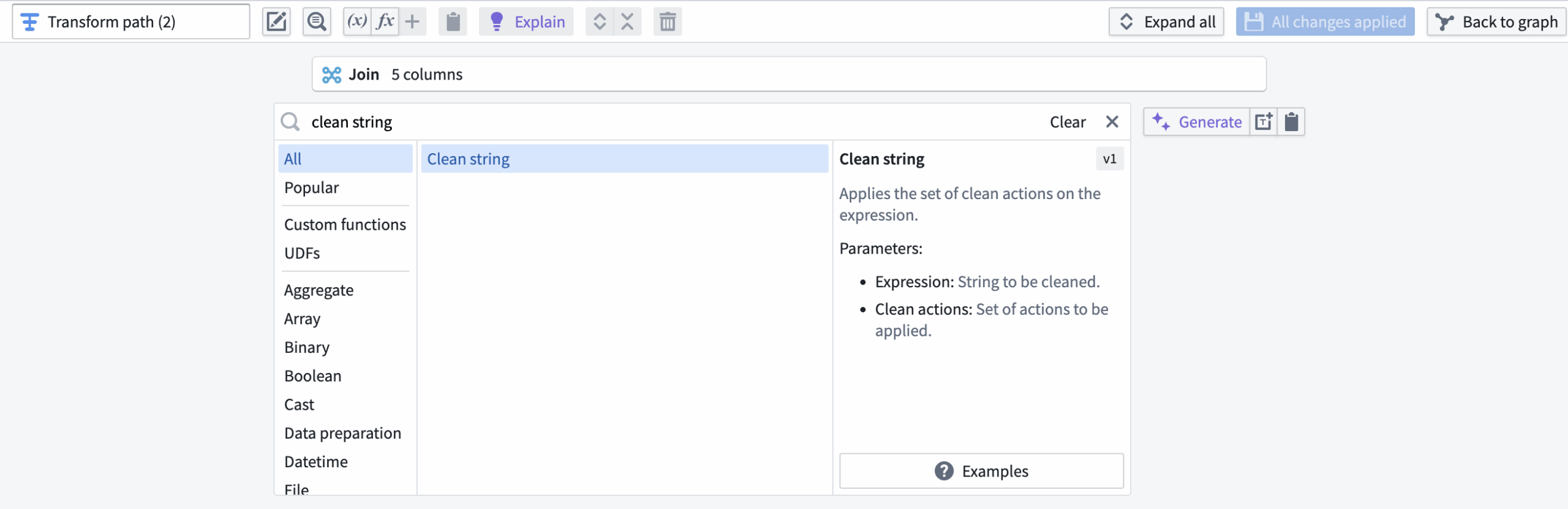
It is very intuitive to search for the transformation appropriate for the user’s needs, which means that the development of such pipelines can be adopted by a wide range of users, technical or otherwise. Furthermore, if a user is looking for a more complex workflow and doesn’t know which transform can help, the Artificial Intelligence Platform (AIP) generation features allow developers to write the transform descriptions using natural language, and the platform will generate the proper steps. For more information about AIP features, you can refer to our article on Palantir AIP.
Another interesting aspect of Pipeline Builder is its quick visualization of the data at each transformation step, which enables users to rapidly iterate during the development process. This also includes the setup of various data expectations, such as primary key checks, checks for null values, etc., which can ensure better data quality.
Enhancing Data Quality
There are two axes along which we can enhance data quality: 1) transforming the data to conform to technical constraints, such as the target data system’s requirements, and 2) enforcing business quality rules set up by the company.
Complying to technical requirements
Let’s take SAP as an example of a target ERP system in a data migration workflow. Through the Data Connection application that we mentioned previously, it is possible to extract metadata from SAP about the various tables in order to construct a dataset with all the rules that the data must follow (primary key, data types, mandatory columns, etc.). This dataset construction can notably be done in the Pipeline Builder application mentioned earlier.
This process is particularly important since it forms the core of the rules that all of the datasets to be migrated into SAP must follow. For example, we can extract from the metadata that, in the MARA table, the column MATNR is the primary key and therefore elements from that column must be non-null and unique.
Once this metadata dataset has been built, we can build the logic with either Pipeline Builder or Code Repository (a platform-integrated IDE on AIP) to compare our datasets with the metadata and thus create a dataset containing all rows flagged by the logic.
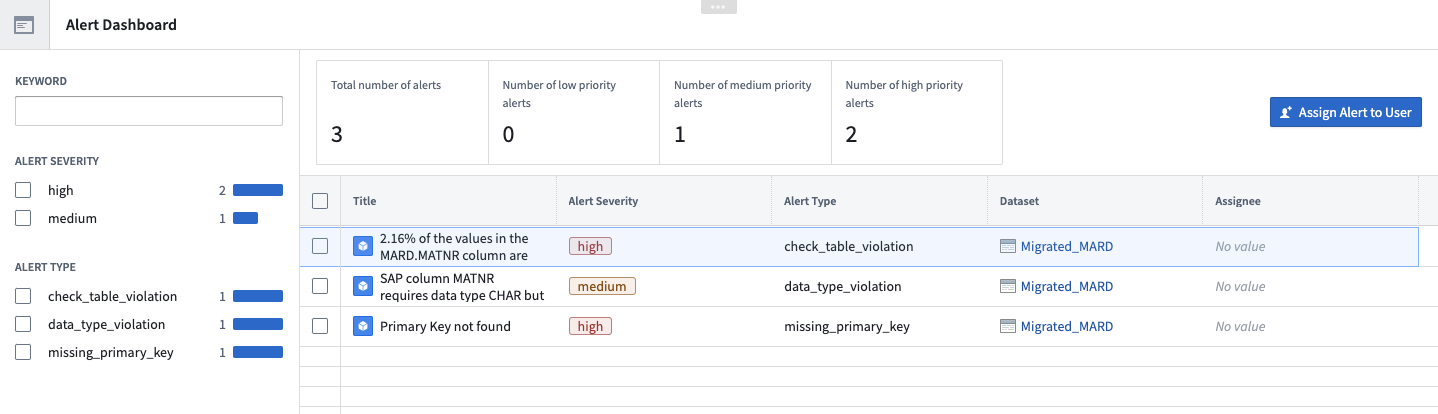
This is when the Ontology layer comes in, and an interactive dashboard application can be created in order to manage and keep track of these alerts. Here is an example of such an application:
Enforcing business logic
Among the wide array of applications, Foundry Rules is the one that enables users to write rules detailing how their datasets should be according to business requirements.
Once the Foundry Rules application is configured, any user can start authoring rules on each dataset by defining a succession of transformation boards, which are easy to configure. The design of the Foundry Rules application will remind users of the Contour application. This is because it is also possible to first design the rules workflow in a Contour path and then import it into the Rules application.
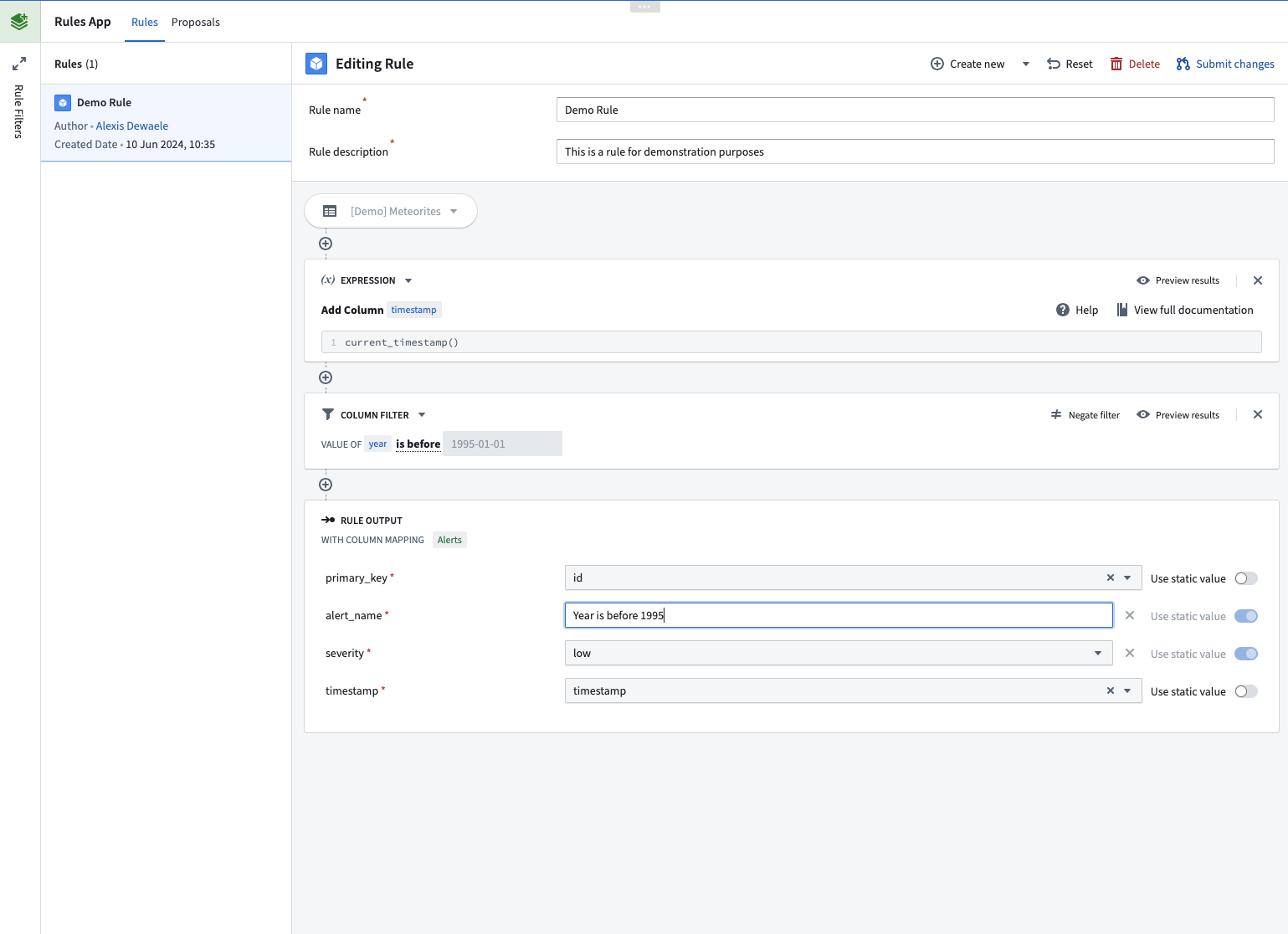
In the example, we have drafted a simple rule on the [Demo] Meteorites dataset to first create a timestamp column and then apply a filter to verify if there are rows where the column “year” is before January 1st, 1995.
Once the rule is authored, we need to submit our changes, and a proposal is created. This can be reviewed by other users, who can see what the changes are and either accept or reject them.
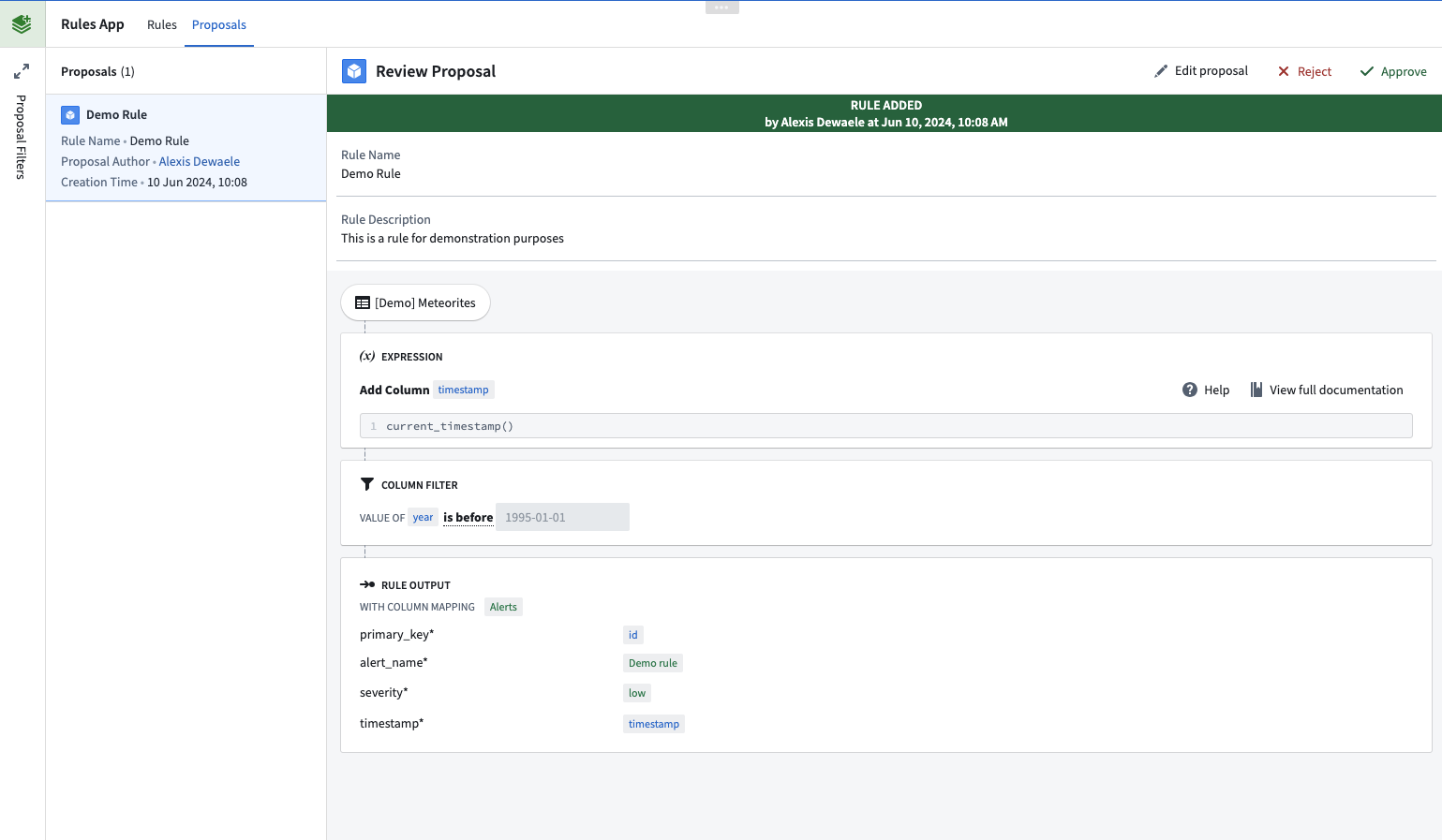
Then, if the newly proposed rule is accepted, it is written back into the Ontology. The final step to run this alerting process and compare our datasets with the rules is to use the Data Lineage application to build the alert dataset regularly.
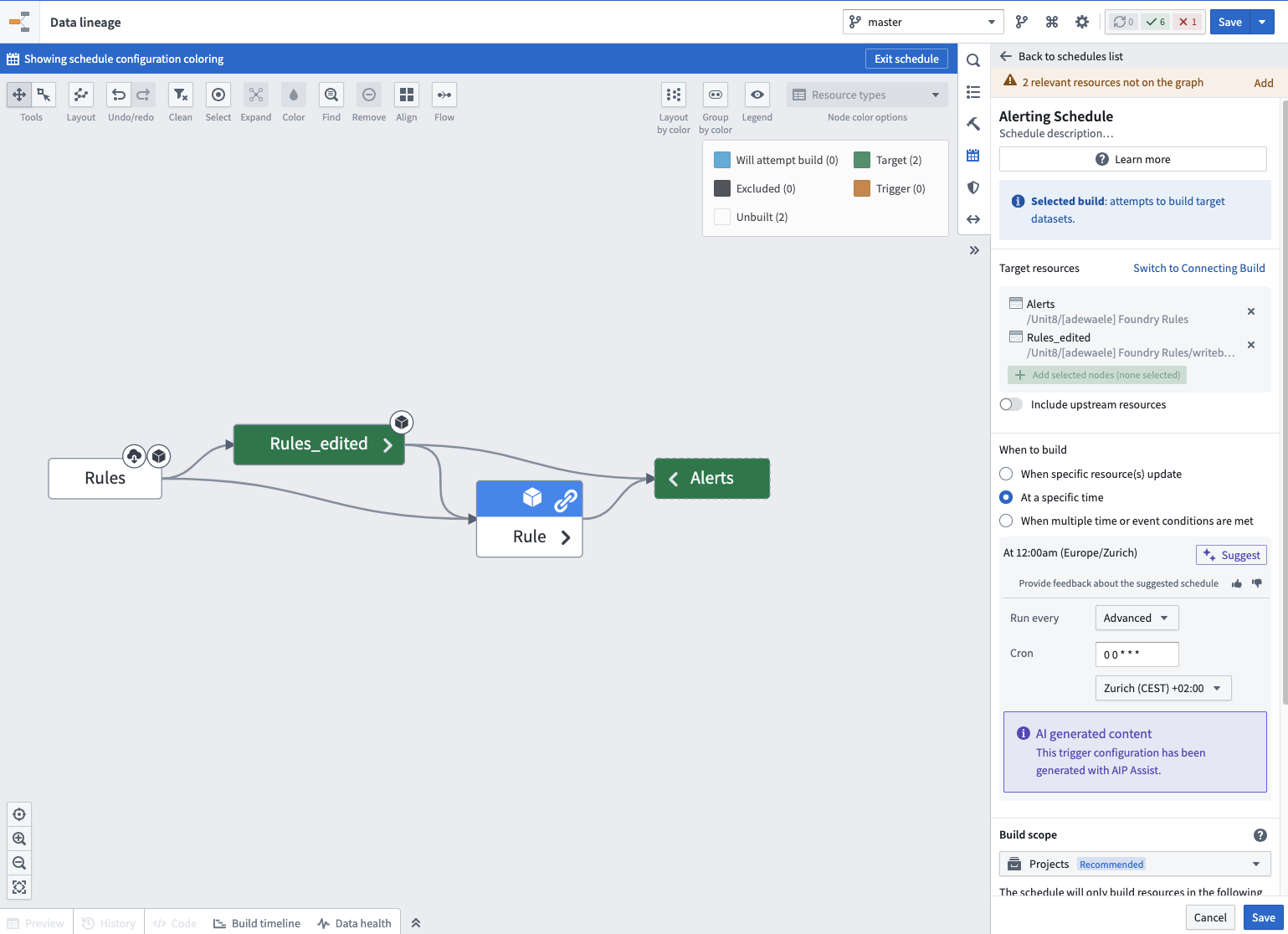
Now that the Alerts dataset is built, we can apply analytics to it with different applications, such as a Contour analysis or a Workshop application. Let’s use the Ontology layer to model the Alerts dataset and build a dashboard that will empower users to manage these alerts and solve data quality issues.
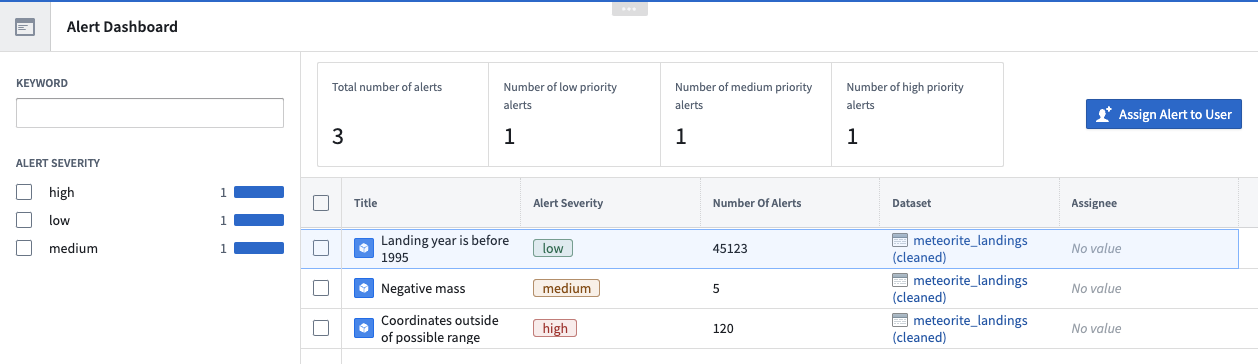
In this simple dashboard, a user can see all alerts raised by the workflow and assign them to other developers. When someone solves a data quality issue, whether by correcting the data upstream or deleting the offending rows, the dashboard will update along with the rules and alerts datasets.
Conclusion
Palantir AIP is a versatile end-to-end system that empowers both business and technical users to develop complex data migration pipelines, from raw data ingestion through a data quality enhancement framework to a target ERP solution. Onboarding new users is swift. Our past experience shows that it is possible to teach a small group of business experts with no data engineering background how to build an end-to-end migration workflow and make use of the full capabilities of AIP. They were able to experience how AIP’s features, such as out-of-the-box data connections, data quality enhancements, and business-focused custom workflows, surpass traditional tools such as Microsoft Excel.
Enhancing data quality through AIP builds a strong data foundation, which empowers businesses to develop more advanced use cases, such as an interactive KPI management dashboard or a Supply Chain Control Tower application.
If your company is facing challenges with outdated or multiple ERP systems, or if you are interested in learning more about the business value of consolidating your data architecture and ERP landscape, we invite you to reach out to Unit8. Our team of experts is ready to help you navigate these complexities and unlock the full potential of your data infrastructure.


