
- Dec 18, 2024
- 10 minutes
Written By
-
 Yassir Benkhedda
Yassir Benkhedda
Large language models (LLMs), such as ChatGPT have become widely adopted to prototype and explore generative AI (genAI) use cases. These models make it relatively straightforward to build a proof of concept (PoC) and demonstrate technical feasibility. However, going from a simple PoC to a robust, production-ready system introduces many new challenges, from handling real-world data complexity to ensuring reliability and scalability.
In this article, we’ll explore how to transition your use case from PoC to a minimum viable product (MVP). We’ll look at the importance of defining user interactions, leveraging evaluation-driven development through data collection, and adopting a modular architecture to address scalability and adaptability. The focus will be on application design and development rather than the infrastructure or tooling that supports it.
1. Developing the PoC
The journey of developing a PoC begins when business teams identify a use case to explore using LLMs, with the primary goal of validating technical feasibility. Creating an initial prototype is often straightforward and typically involves three key steps: data preparation, retrieval and output generation.
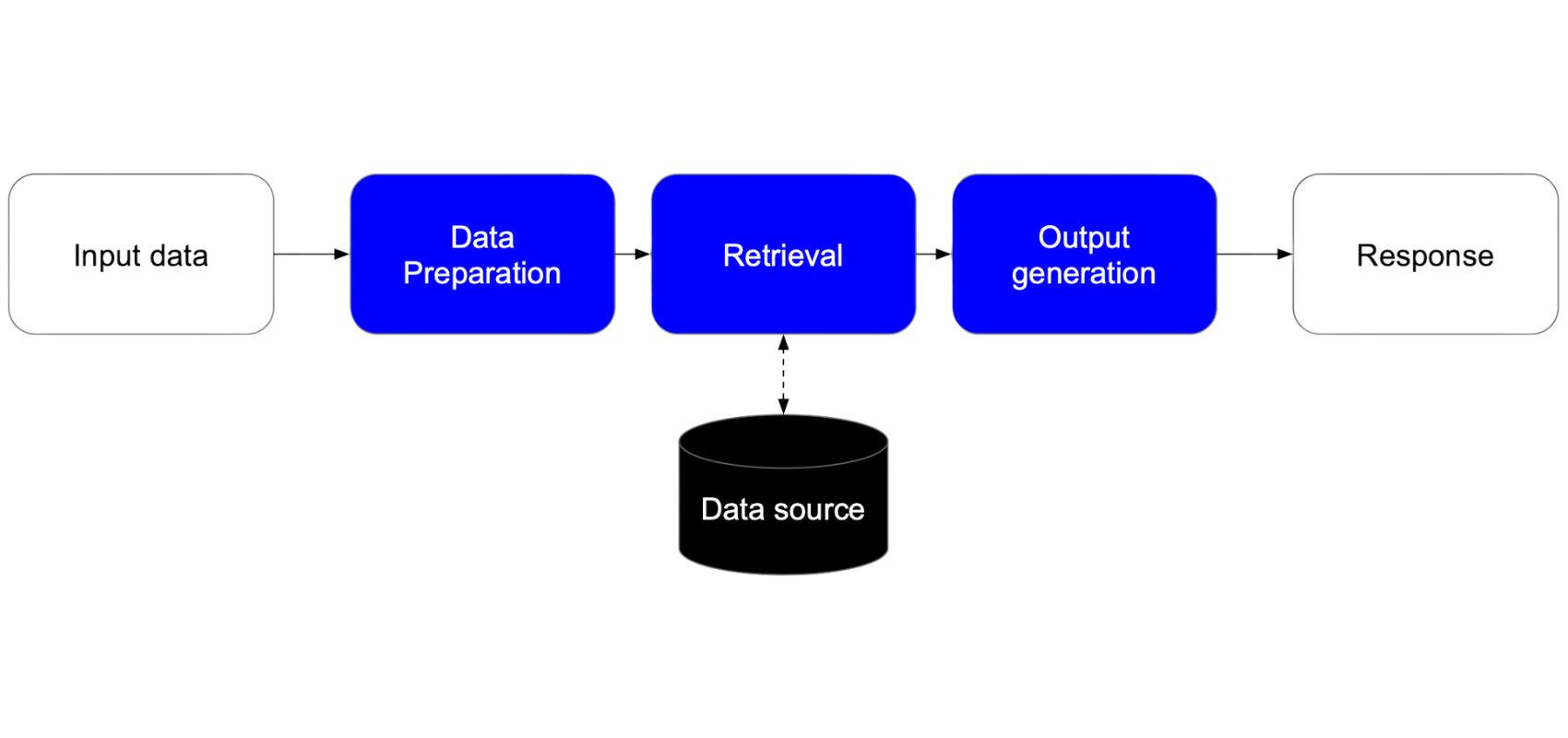
While these high-level steps remain consistent, variations in implementation depend on the use case and the nature of the input data.
- Data preparation
In this step, input data is cleaned and transformed into a standardised format. This includes parsing different input data types, resolving inconsistencies to ensure data quality, and normalising data for downstream use. This may not be necessary in the case of simple user inputs. - Retrieval
The retrieval step finds the relevant context needed to solve the task at hand. Semantic similarity search is a widely used approach for retrieving relevant text, particularly from a large corpus of unstructured text. Metadata-based filtering can help refine searches from more structured datasets, In cases with smaller amounts of text such as a single document, the LLM can be leveraged directly to identify relevant parts. Tabular data and external systems can be integrated using generated SQL queries or API requests. - Output generation
This step generates the expected output based on the correct context provided by the retrieval step. For instance, we can generate natural language responses such as summaries in the case of a chatbot or structured data such as JSON in the case of data extraction. It can also be a mix of both structured and unstructured data such as extracted meta data along with a textual explanation of the results. - Validating the PoC
The power of LLMs allows for the rapid development of early prototypes, which are typically validated through qualitative methods, such as manually reviewing outputs on a few examples to ensure they align with expectations. Ideally however, we should have some basic evaluation pipeline even on a single example that can serve as a baseline. In the next section we will look at important factors to successfully transition beyond the PoC phase.
2. Going from PoC to Minimum Viable Product (MVP)
After a successful PoC and organisational buy-in, the focus shifts to developing an MVP. This phase involves refining user interactions, expanding the solution’s scope, and improving performance. Unlike the PoC, which relied on qualitative evaluation, the MVP must perform reliably across a broad set of scenarios. Evaluation-based development ensures the solution is robust while modular system design helps manage the increased complexity, enabling future scalability and adaptability.
2.1 Defining the User Interaction
In AI applications, user interaction is tightly integrated with solution design, more so than with typical machine learning projects, due to the flexibility in defining workflows. Aligning the system with user expectations and addressing pain points is critical for success. Key considerations include:
• Interpretability: Helping users make sense of outputs through techniques like chain-of-thought to see the thought process of the system and retrieval to show which retrieved data was used to produce the answer.
• Highlighting Problematic Outputs: Guiding users to focus on likely errors not to double-check all the generated content. We can use LLM-based or rules-based checks to spot potential inconsistencies.
• Placement of Human Feedback: Deciding when users should provide input, with early feedback preventing error propagation. Also, in the case of ambiguous, missing or invalid data.
• User-Augmented Prompts: Allowing users to adjust or extend prompts for greater control over model outputs.
2.2 Extending the Solution Scope
During the PoC phase, the solution was likely tested on a small set of examples that did not reflect the full complexity of real-world data. In reality, input data often follows a long-tail distribution where a few common examples account for the majority of cases, while many edge cases occur less frequently. Successfully expanding the scope means understanding and addressing both the frequent scenarios as well as the less frequent edge cases the system should handle.
Challenges with input data often come from:
• Format variability: Data can come in a wide range of formats, layouts, languages, and sizes making it hard to create a one-size-fits-all solution. For example, scanned documents may need to be handled differently to digital documents.
• Quality issues: Incomplete, inconsistent, or otherwise noisy data can hinder system performance. For example, missing fields or conflicting values might require additional logic.
To manage these challenges, it’s important to define the system’s boundaries:
• Input Scope: Identify and prioritise the types of data the system will handle initially. If there’s too much variation, focus on a prioritised subset for the first version. For instance, if working with multilingual documents, start with the most common languages.
• Output Scope: Determine what the system should produce, especially when dealing with ambiguous or incomplete data. For example should the system flag missing fields or fetch the data from another system.
The goal is to balance handling enough variation to be useful without getting overwhelmed from the start. Understanding and managing this complexity leads us to the next topic of data collection and evaluation driven development.
2.3. Dataset Collection: Evaluation-Driven Development
Extending the solution’s scope requires a dataset that reflects the complexity of the data the system is expected to handle. A well-constructed dataset serves multiple purposes:
- Identifying failure cases: Highlights weaknesses in the system and areas for improvement.
- Benchmarking performance: Provides a clear measure of system performance
- Ensuring stability: ensures that newly introduced changes don’t negatively impact performance on previously tested examples.
Types of Evaluations
Evaluations take different forms, including end-to-end testing and component-level testing. End-to-end testing usually involves comparing the output of our system against some expected output. This works well for structured outputs, but for freeform outputs such as text, more nuanced approaches like using LLMs for evaluation are needed. LLMs can be used for evaluations but we need to also validate the evaluation itself. Component testing focuses on evaluating specific steps in the system. For example, a retrieval step may be tested to ensure it correctly retrieves relevant information, avoids missing critical parts and does not retrieve irrelevant data.
Types of Data to Collect
The dataset may be extended in two ways: by including new edge cases and by adding similar examples to the existing dataset. New edge cases help broaden the scope of the dataset to become more complete. Similar examples, on the other hand, are useful for increasing test robustness and help provide a more accurate estimation of system performance.
2.4 Improving performance
With a diverse dataset and a clear understanding of the system’s failure cases, the next step is to focus on improving performance. These improvements generally fall into three categories: prompt engineering, task design and context management. An additional option is fine-tuning in the case of a sufficiently large and diverse dataset.
1. Prompt Engineering
Refining Prompts: improving the clarity and specificity of system prompts can help align outputs with expectations. However LLMs do not always adhere perfectly to instructions so gains from this method tend to plateau.
Few-Shot Learning: adding examples of expected behaviour in the prompt to guide the model more effectively than instructions alone. This is particularly useful for addressing edge cases that are difficult to articulate but easier to demonstrate through examples.
Chain-of-Thought Reasoning: allowing the model to “think aloud” before providing the final answer. This can be particularly helpful for more complex multi-step tasks where intermediate thoughts help provide context to more accurately produce the final answer.
Prompt generation: dynamically generating tailored prompts based on the input data type or tasks requirements can further optimise performance. For example depending on whether the input contains tables or not we might have a modified prompt.
2. Task Design
Breaking down tasks: Some tasks are too complex for the model to handle in a single step. Dividing them into simpler subtasks can improve accuracy. For example, when extracting multiple features from a document where the relevant information is scattered across different sections, we can break down the task into multiple steps that extract different subsets of features separately, with focused prompts.
Fallback Mechanisms: When failure cases are predictable, fallback mechanisms can provide a safety net. For example, if the system is expected to output JSON and produces invalid results, a secondary prompt can be used to request a corrected output. Similarly, issues like unordered lists or missing data can be flagged and addressed with automated corrections and targeted prompts.
3. Context Management
Improving context retrieval: The quality of the context provided to the model is critical. Missing information makes it impossible to produce accurate outputs while excessive noise can also hurt performance. Enhancing the retrieval mechanism with more accurate extraction of relevant information is a sure way to improve system performance.
Applying the Strategies
These strategies are not standalone solutions but part of an iterative improvement process. For each failure case, it’s essential to analyze the root cause and decide which combination of prompt engineering, task design and context management is most suitable. By systematically applying these techniques, the system can evolve to handle greater complexity with higher accuracy and reliability.
2.5 A Modular Approach
Building complex systems with LLMs can be challenging, in particular when multiple LLM calls are involved and require coordination of inputs and outputs. Adopting a modular design approach, inspired by software engineering principles, can help create a scalable and maintainable solution.
With a modular architecture, the system is broken down into multiple steps, each corresponding to a specific task with a clearly defined scope. These steps are connected in a graph-like structure, where the output of one step feeds into the next. This design allows for flexibility and ease of updates, as changes in one step do not necessarily impact others.
Benefits of a modular design include:
• Separation of Concerns: Each step focuses on a specific aspect of the problem, reducing complexity and making the system easier to understand and maintain.
• Clear Interfaces: Well-defined interfaces between steps ensure smooth interactions, so changes within a step won’t disrupt the entire system.
• Independent Evaluation: Steps can be tested and improved independently, allowing for targeted improvements without affecting the whole system.
• Flexibility to Extend: New features or requirements can be integrated more easily, as the modular structure accommodates extensions without widespread changes.
There can be different types of steps within the final graph such as:
• Extraction steps: Perform straightforward transformations on input data to produce a single output.
• Conditional Logic Steps: Decide the next action based on certain conditions, similar to if-else statements. For example, selecting a different processing path based on user input.
• Iterative Processing Steps: Making LLM calls within a for or while loop, such as processing each item in a list or repeating an action until a condition is met.
• Aggregation Steps: Combine outputs from multiple steps to produce a unified result, such as merging data from different sources.
• Recovery Steps: Handle unexpected outputs by dynamically adjusting the input, for example by extending the original list of messages sent to the LLM with additional context on what to fix. We can have multiple recovery steps based on the issue found.
In languages like Python, you can represent each step as a class that can be parameterised and instantiated in the graph.
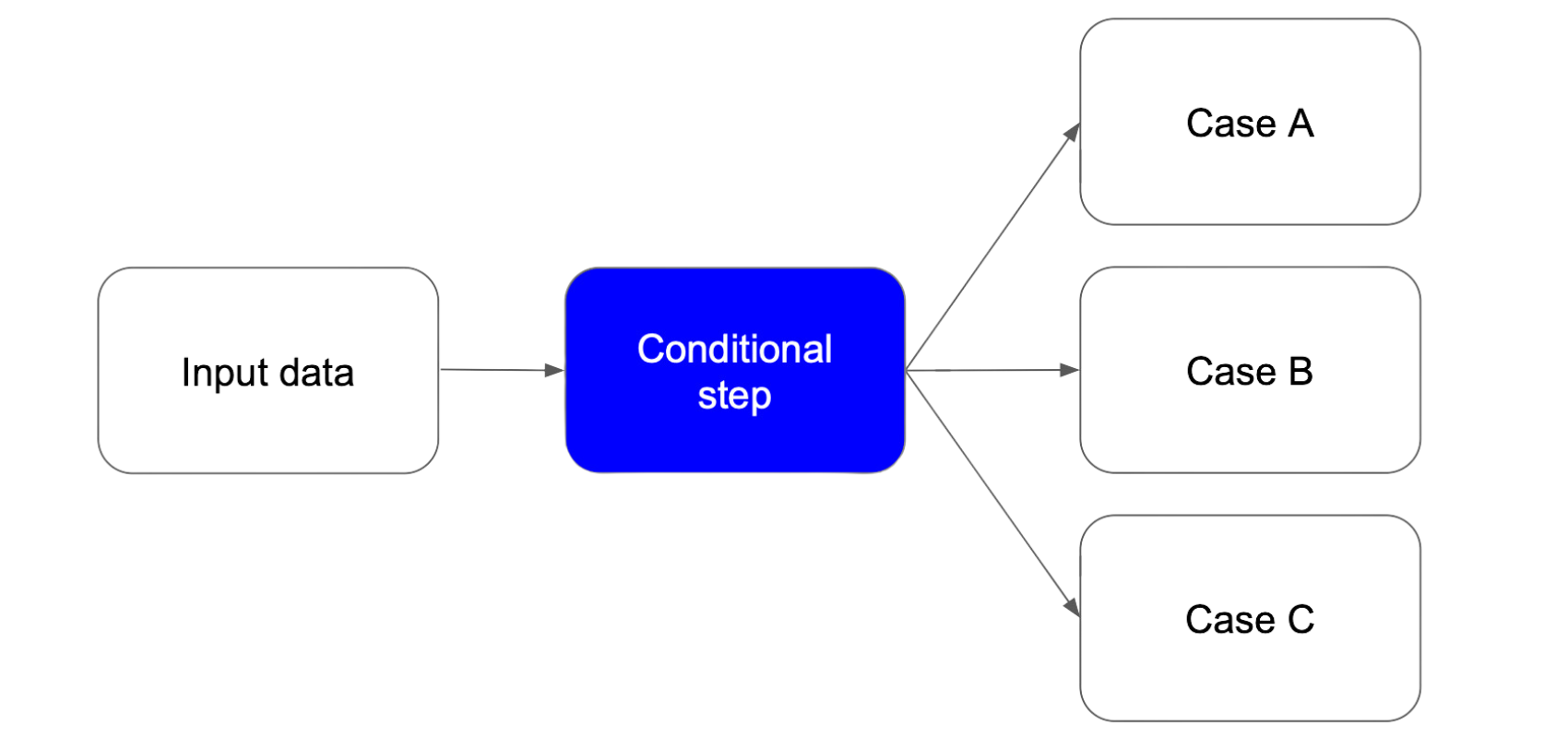
Conditional step takes a single output and based on which condition is met will take one of the multiple possible next steps.
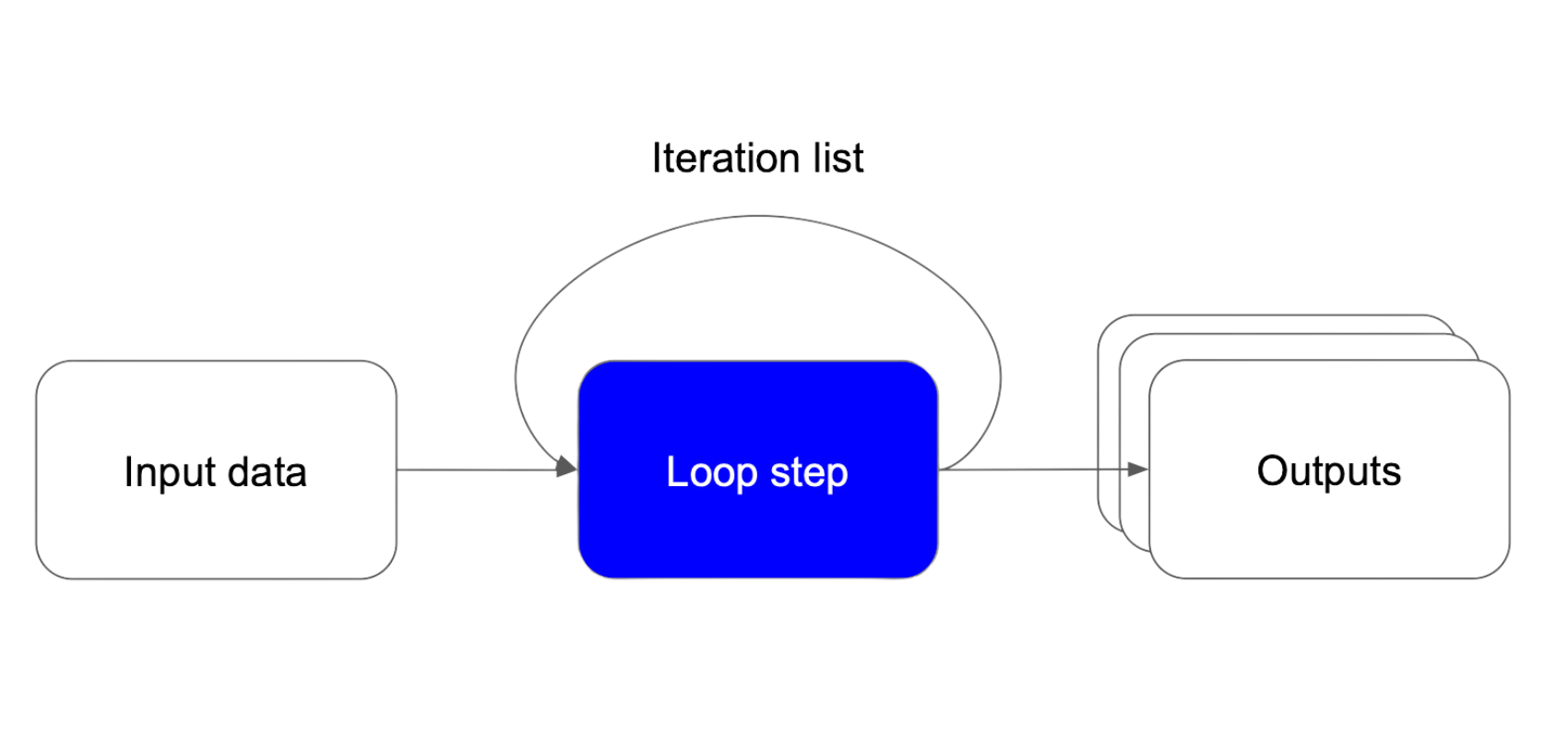
Iterative step will loop based on some iteration list to produce multiple outputs per each item in the list.
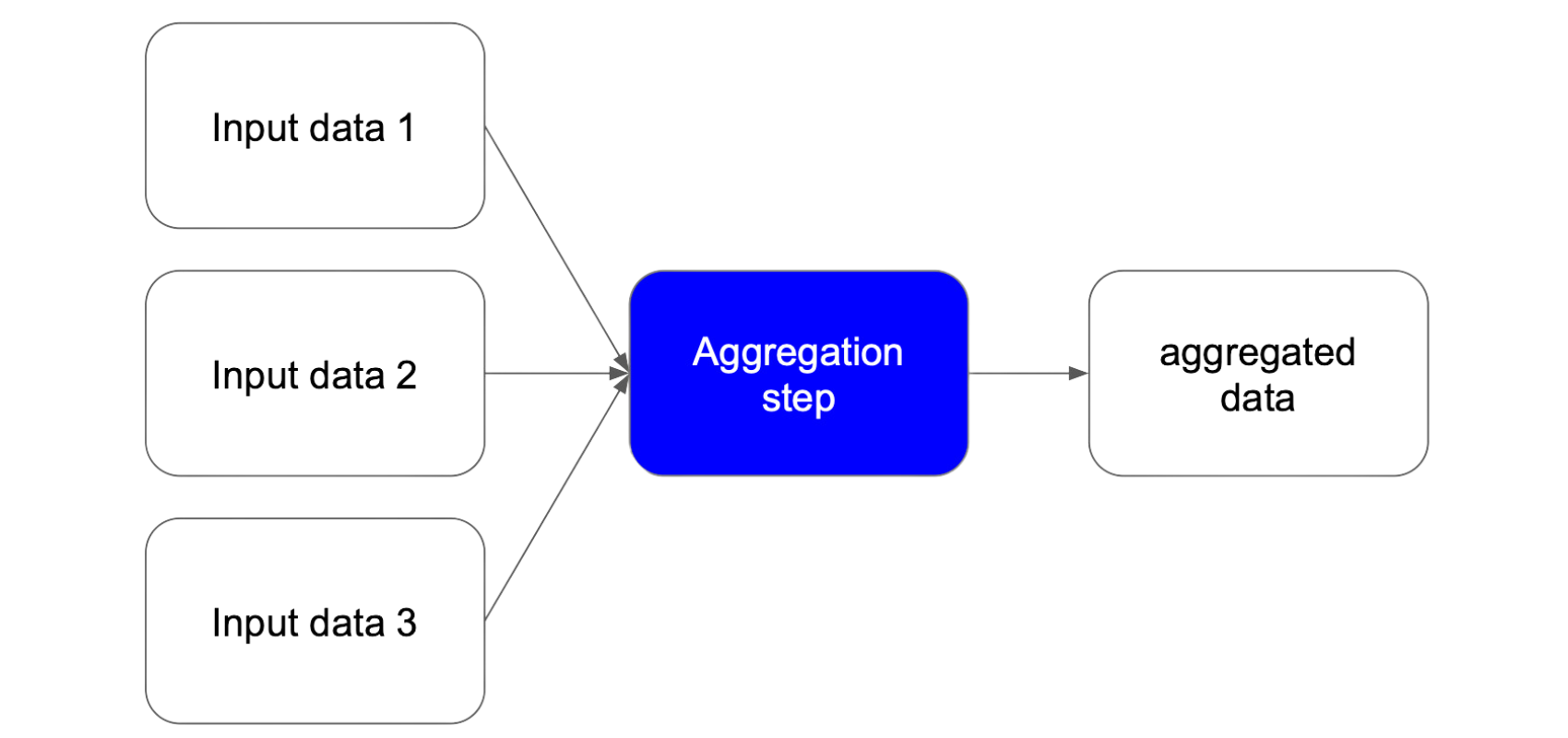
Aggregation step takes multiple inputs and aggregates them to produce a single output.
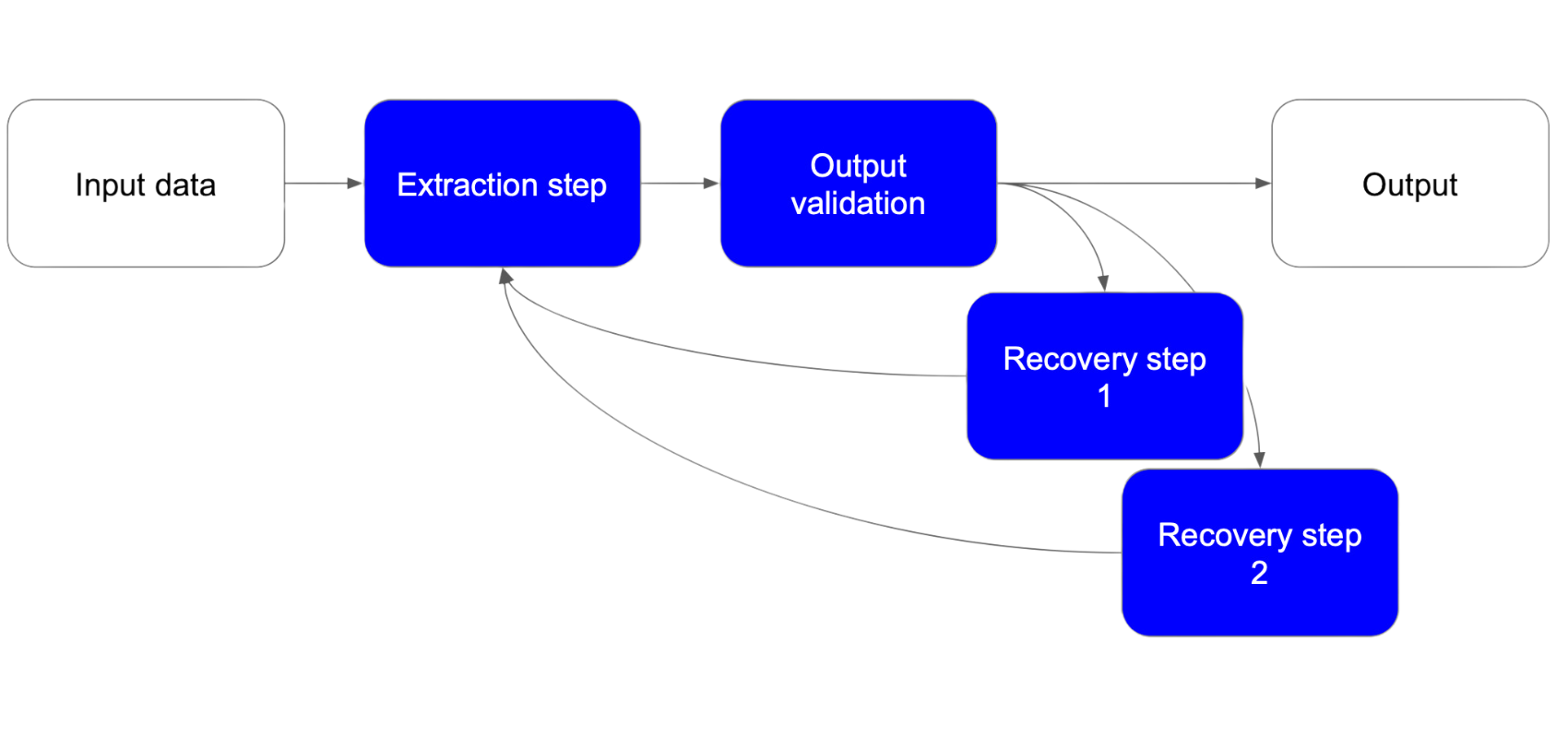
Recovery steps are called if an extraction step produces a faulty output, they can make modifications to the extraction step to retry.
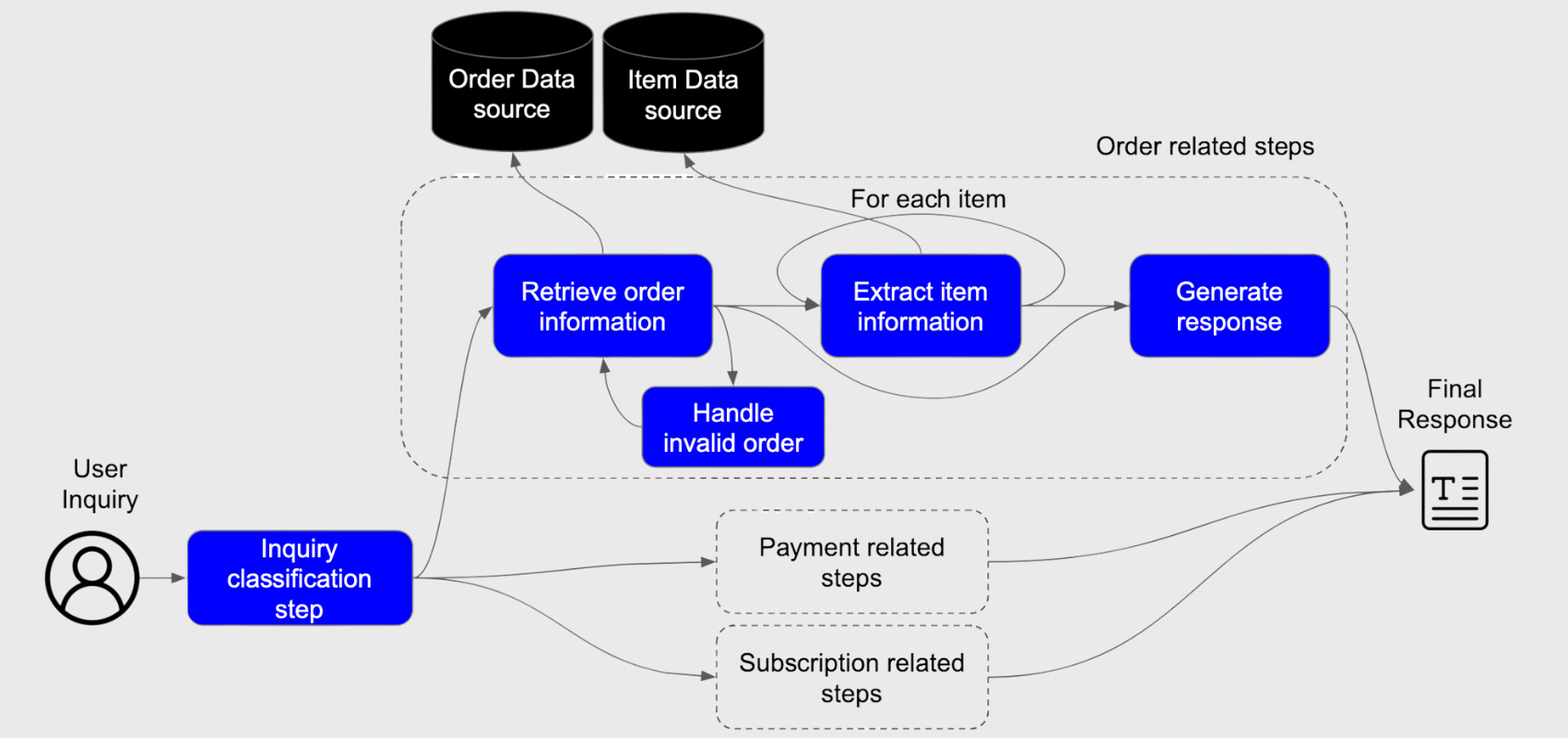
Let’s take an example of an app designed to handle customer service inquiries. A modular workflow with multiple LLM calls can structure this process effectively. It starts with classifying the inquiry to identify its type—such as order-related, payment-related, or subscription-related. For an order-related inquiry, the system retrieves the relevant order details, including a recovery step to handle invalid or missing orders. Next, it processes each item in the order to extract specific information. Finally, the item and order details, along with the user’s original question, are passed to a step that generates a final textual response to the user. This modular design ensures flexibility and scalability for handling diverse customer service tasks.
2.6 Agentic Systems
The concept of agentic workflows often comes up in discussions about advanced AI applications. These workflows are powerful because they enable dynamic decision-making, allowing systems to determine the sequence of tasks at runtime. However, they are challenging to implement in practice and not always necessary, as many use cases can be effectively handled with predefined flows that are easier to implement and maintain.
Agentic workflows are most relevant when the sequence of tasks cannot be determined in ahead of time. In these cases, an “agentic reasoning” step dynamically evaluates the context, selects the right tools to call, and constructs a unique process flow for each run. While promising, these workflows are challenging to build reliably, especially since current LLMs lack the consistency needed in high-level planning tasks.
For many practical applications today, predefined workflows with modularity and conditional logic are sufficient. As LLMs improve, the potential for agentic workflows to address more complex use cases will grow.
Conclusion
Building AI applications that can handle real world complexity is a challenging task. Significant effort is required in data collection and evaluation to identify failure cases while improving performance involves creative problem-solving using multiple methods, from refining prompts to optimizing task design. A modular design can help build a performant and scalable solution. Finally, the flexibility of LLMs offers unique opportunities to shape user interactions. By addressing these challenges, we can create AI systems that are both practical and reliable for users.



