- Nov 7, 2022
- 12 minutes
Today over 70% of organizations are hosting more than 50% of their workloads in the cloud, and cloud adoption has grown by 25% in the past year (source). Cloud providers keep releasing new services at astonishing speed, constantly reducing the barrier for companies to start their cloud journey. For example, AWS offers over 200 services and the number is still increasing. Individual services evolve as well, new features are added which often open new possibilities and give opportunities to simplify existing solutions.
My name is Blazej Fiderek and I am a Data and Analytics professional at Unit8, a Swiss data, and AI service provider. During my work, I design, implement, assess, scale, and enable Data Platforms. Recently, I had the opportunity to work on the rebuilding of a few years old Data & Analytics platform hosted on Azure. I could propose improvements and changes as well as check how new features of Azure and paradigm shifts influence and often improve the design of data platforms.
In this blog post, I would like to share what I learned. I am going to
- Outline the architecture, key successes, and pain points of the previous solution
- Discuss how new data and analytics platform built from scratch can address discussed impediments
- Mention some of the technical challenges that companies still need to face today despite recent advancements in cloud services
After reading this article, you will see that some of the latest features of Azure vastly simplify platform design and operations, but also that they have certain caveats and limitations, which need to be reviewed thoroughly by architects. There is a lot of room for improvement, especially in terms of data governance, but solutions are on the way.

Platform 1.0: Background story
Around 5 years ago our client decided to invest in a company-wide Data & Analytics Platform and chose Microsoft Azure as a cloud vendor. The main goal was to create an environment that would enable fast, secure, and compliant development of Advanced Analytics solutions.
Looking at the number of users, solutions created, and end users benefiting from the platform it is fair to say that the investment was worth it.
Having said that, some key architectural decisions have been made at the beginning that limited the flexibility and increased the operational cost of running the platform.
Key design decision #1: Centrally managed data lake(s)
The platform was built on Azure on top of two data lakes.
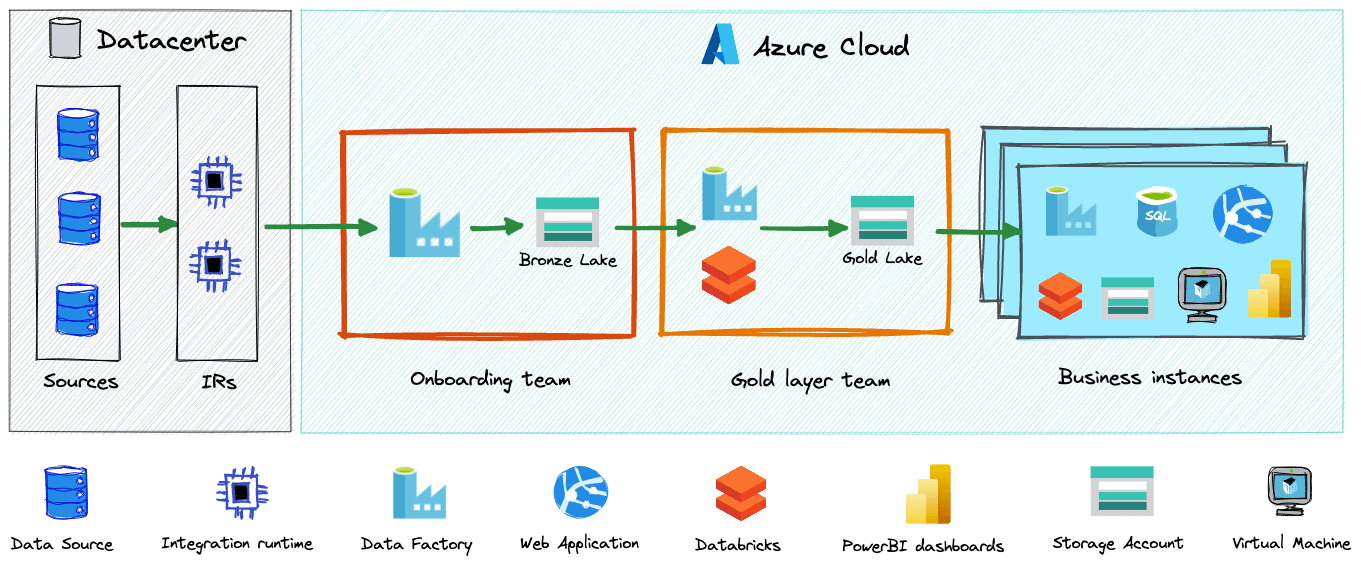
The central team was ingesting data from the on-premise data center to the first lake (let’s call it Bronze lake). For most of the sources, another team was building a curated layer (Gold lake) on top of the data from the Bronze lake. Several instances from different business units were building use cases on top of the data from Gold Lake – mostly web applications or dashboards in BI tools.
What are the main limitations of this approach?
One of the outlined pitfalls of such an approach was the dependency on the central teams. This architecture does not scale well and increases time to value.
Another problem was that business instances often created insightful datasets and wanted to share them with other instances. Although it was technically possible to share the data, there was no framework or best practices defined for such scenarios.
Key design decision #2: “Closed“ network architecture
So far we took a look at the logical data flow, but another piece worth discussing is the network setup, which on the high level looked more or less like this.
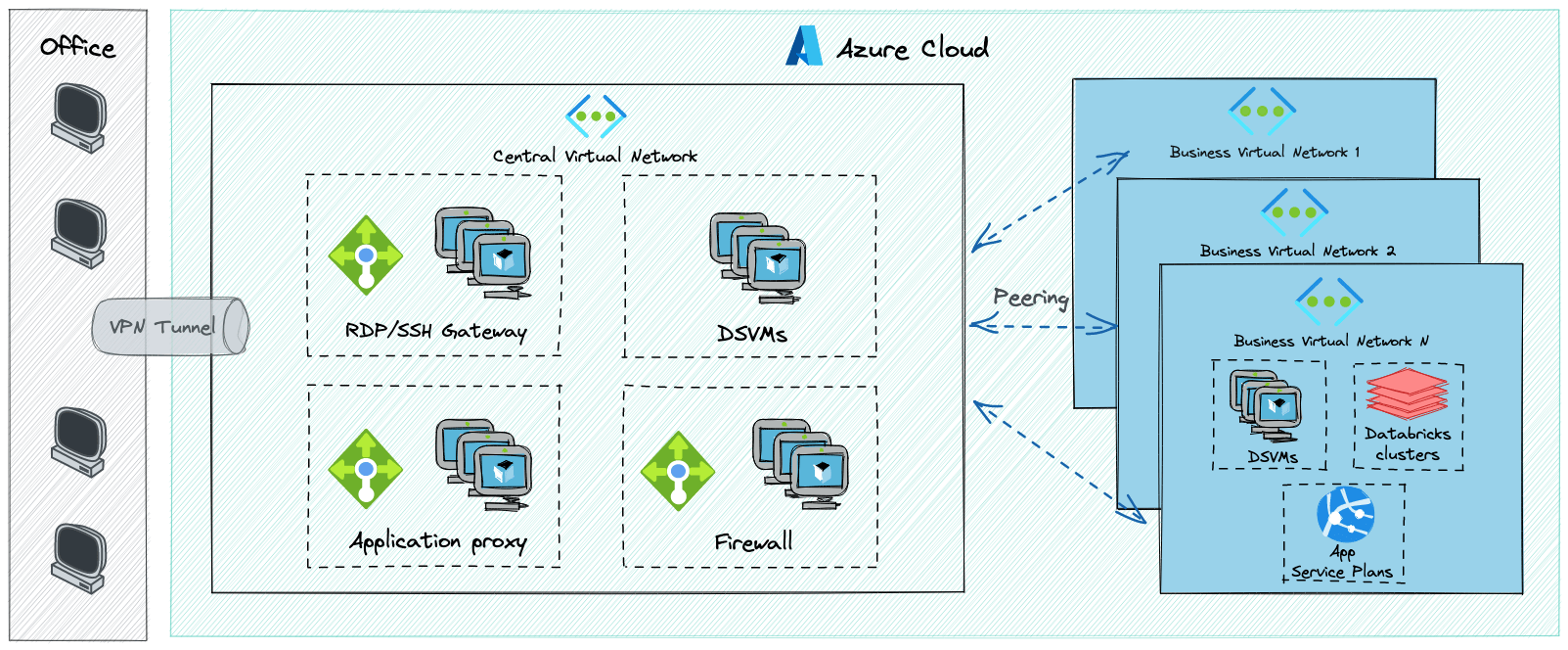
The initial architecture consisted of multiple gateways, proxies and virtual appliances.
What are the main limitations of this approach?
This setup made network design and operations much harder. Firewall and proxy software deployed to virtual machines had to be patched and maintained by the central operations team. Moreover, some of the parts of the infrastructure still relied on legacy authentication methods, such as key-based authentication.

Platform 2.0: Possible improvements
Recent paradigm shifts such as treating data as a product suggest that we should rethink the way we build data platforms. On top of that, the rapid growth of SaaS and PaaS components combined with the pay-as-you-go model makes it much easier to start, experiment, and build use cases.
In this section, I outline a few examples of improvements to the reference infrastructure discussed above. We will discuss the following points:
- Decentralizing data teams
- Using services available on Azure instead of customer-managed software
- Simplifying network setup and authentication
Improvement #1: Decentralizing data teams
Having central ingestion and data curation team is always a tradeoff. Such a team can offer high-quality data by means of well-written data pipelines, top-notch monitoring standards, and well-defined strategies for failures. On the other hand, the central team can often be a bottleneck that increases time to value and creates confusion due to a lack of understanding of data.
On top of that evolution of data engineering tools made them easier to use by less experienced teams. If we want to treat data as a product, it is worth bringing domain experts and data owners as close ingestion layer as possible, to create valuable assets faster and avoid misunderstandings.
If Azure Data Factory is used for ingestion, decentralization can be done in several ways. Each approach has its own pros and cons and the decision depends on the organization’s policies and requirements.
The diagram below outlines possible decentralization by using Integration Runtime Sharing.
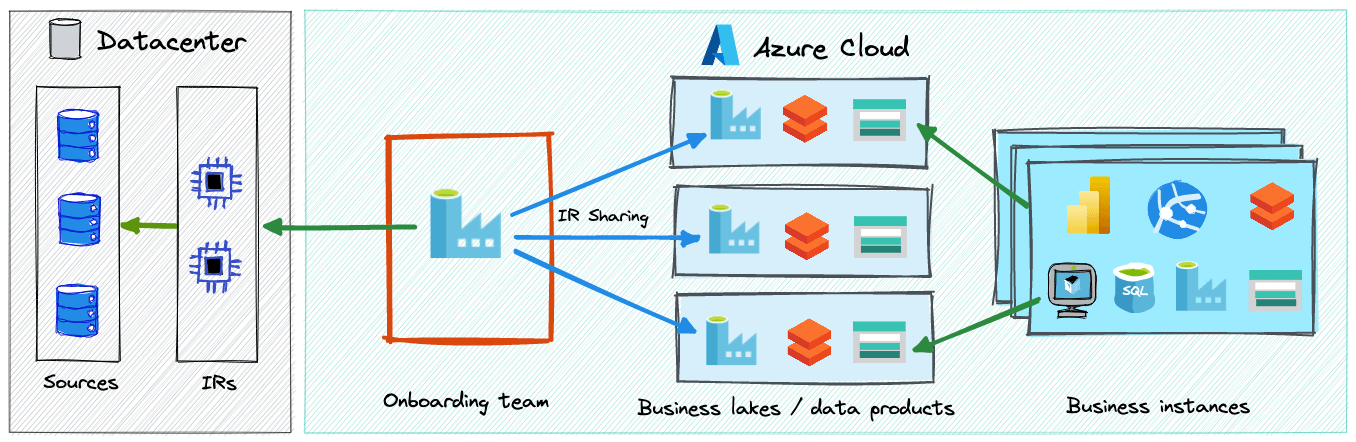
Decentralization helps to define clear ownership and reduce time to value, however it also requires much stronger governance. This can be achieved with help of the central data team, which during transition can focus on enabling other teams by sharing best practices as well as common standards and frameworks for development, monitoring and data access management.
Improvement #2: Using services available on Azure instead of customer-managed software
Some of the solutions that previously had to be managed by IT teams, such as firewalls or gateways are now offered by Azure as managed services and in many cases are mature enough to meet both performance and regulatory requirements of many enterprises.
Managed solutions can help to:
- make infrastructure much simpler
- make integration with other Azure components easier
- reduce operational time and cost
- Centralize logging and monitoring by native integration with Log Analytics and Event Hubs
- Increase security
Below you can find several examples of managed services available on Azure.
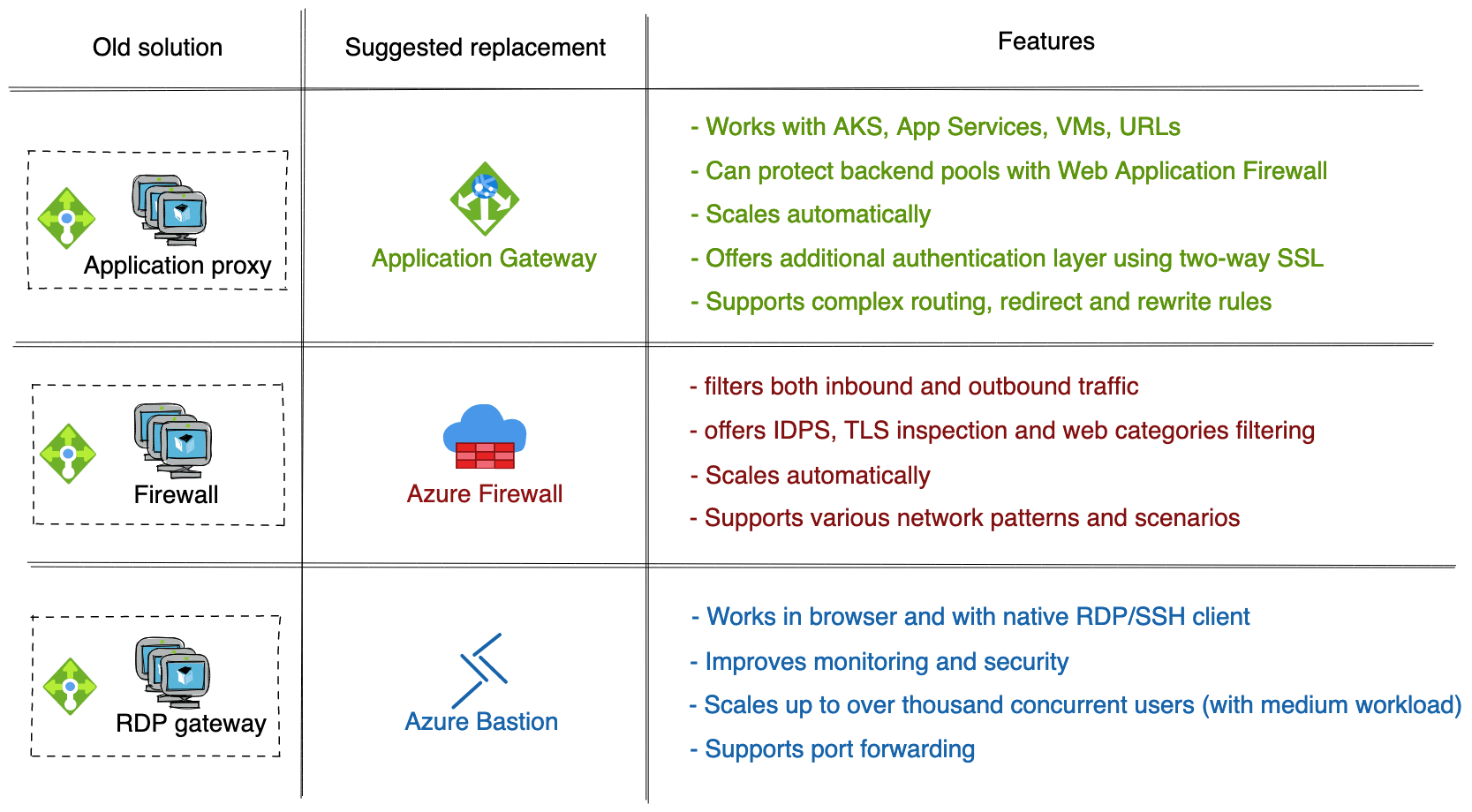
Improvement #3: Simplifying network setup and authentication
Cloud vendors go to great lengths to simplify the hardest parts of operations such as identity and access management or network. Over the past couple of years, many interesting concepts and solutions emerged. In this section, I want to outline some examples of them.
Using resource-based firewall whitelisting methods
Some of the services support firewall whitelisting methods that do not require integration with Virtual Network. Network access can be managed almost seamlessly by whitelisting access to specific instances or using managed private endpoints.
Those methods provide very granular network control that is in line with the zero-trust model. The only drawback of this solution is that it is not supported by all services.
Creating Application Security Groups
Application Security Groups logically group network interfaces together. Created ASGs can be used to control traffic inside subnets. In some scenarios they can save time for planning network architecture of proxies, applications and general-purpose VMs as well as provide more granular and convenient network isolation. Using ASGs makes it easier to build architecture closer to the zero-trust model.
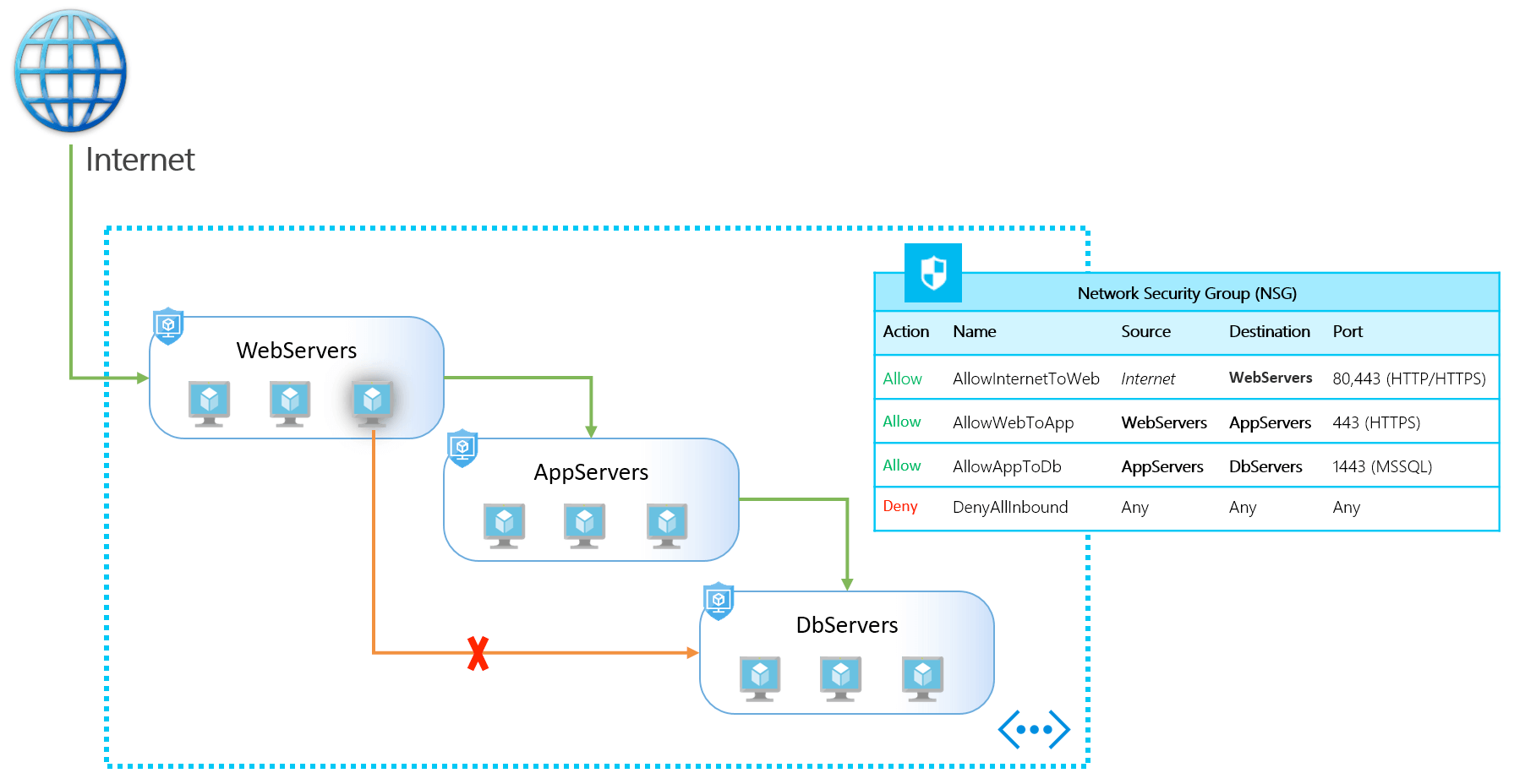
Source https://azure.microsoft.com/pl-pl/blog/applicationsecuritygroups/
Using modern authentication and authorization methods
Nowadays most of the components on Azure support Azure AD-only authentication. No keys, tokens, or local credentials are required, as identities are stored and managed by Azure Active Directory. Such a model enhances security, monitoring and governance over access control.
Also, thanks to managed identities (credential-less authentication method for Azure services) organizations do not need to worry that much about storage, expiry and rotation of credentials for service connections.
But we can do better
Even though in general IT teams can much more easily keep the setup secure and spend less time managing and operating cloud infrastructure, there are still some caveats to mentioned services. Each organization needs to carefully consider all the implications of picking managed solutions over tailor-made software. Also, not all of the new features discussed are well supported by all services. For example, you can not be fully credential-less if you pick Azure Databricks, as the service does not support managed identities as of today. You can only connect to Azure-AD joined Virtual Machines via Azure Bastion using the command line interface. The list goes on and on.
Another problem that usually arises when speaking about managed services is vendor lock-in. Using the lowest common denominator and shifting towards containerized solutions can help to limit it, but also puts lots of responsibility back on customers. On the other hand, most of the services mentioned in the article usually have their counterparts in other clouds and platforms. Despite this, it would be great to see more and more common standards and tools available across multiple cloud vendors to make migrations and multi-cloud connectivity easier.
Another big problem is data governance and sharing. Most of the available solutions, such as Azure Data Share do not support many scenarios and are not actively developed. However, Microsoft is actively working on the solution. The service that aims to solve the aforementioned problems is Azure Purview. It is a relatively young product, with multiple features still in preview, however, I am looking forward to seeing how it evolves and if it stands up to the expectations.
Summary
Managed solutions, PaaS, and SaaS services significantly simplify the design and operations of data platforms, however, new features are sometimes hard to integrate with existing environments. If you realize that your operations team is spending too much time patching virtual machines or upgrading custom software, it might be worth revisiting the current architecture.
Despite challenges, initial investments related to redesign and implementation can pay off in a long run. Paradigm shifts in data management create an additional layer of complexity for building modern and durable solutions. Although for small organizations and early adopters decentralization makes little to no sense, it is worth having it in mind from day one. This way you can make sure that your platform can scale when needed. The main objective is to get value from data as fast as possible. If you get the first signs that your central data team becomes the main bottleneck to achieving this goal, you can already start thinking about alternatives and your strategy for decentralization and governance. Transition can be a very long process both from a technical and organizational perspective. As multiple teams must be involved to make it successful, the sooner you start, the better.
If you have any questions, comments or you are looking for help with your current Data Platform, reach out to us!