
- Dec 29, 2025
- 12 minutes
Written By
-
 Mikołaj Kublin
Mikołaj Kublin
Modern data platforms are moving toward decentralized, self-service models. This makes data more accessible, enabling teams to move faster. But it also brings new challenges for governance, security, and compliance.
We recently encountered this dynamic while assisting a client with the maintenance and development of a scalable data platform based on Snowflake. We enforced a strict governance model for robust compliance and security, provisioning separate Snowflake accounts per use case. Resource creation (databases, schemas, warehouses) was restricted, only allowing users to provision them via self-service stored procedures managed by our team.
The Challenge: The Validation Bottleneck
While this architecture secured the environment, it also created a significant operational challenge. Because complex stored procedures controlled the provisioning logic, they often generated multiple resources and pre-defined roles simultaneously. It became burdensome to validate changes.
For a long time, the client’s team relied on a purely manual process to verify that their procedures and scripts were functioning correctly. This manual approach was not only time-consuming but also prone to human error, creating a bottleneck that slowed down the deployment of new features. To bridge the gap between strict governance and operational agility, we developed a lightweight integration testing framework specifically designed for infrastructure deployed to Snowflake accounts.
A Solution Inspired by Best Practices
Our solution draws strategic inspiration from the DBT testing framework, which has set the standard for data quality assurance. In DBT, developers define quality checks (such as uniqueness or non-null constraints) for SQL models. However, our challenge was different: we were not operating on SQL models, but rather on infrastructure states and procedural logic. Naturally, this required a custom implementation.
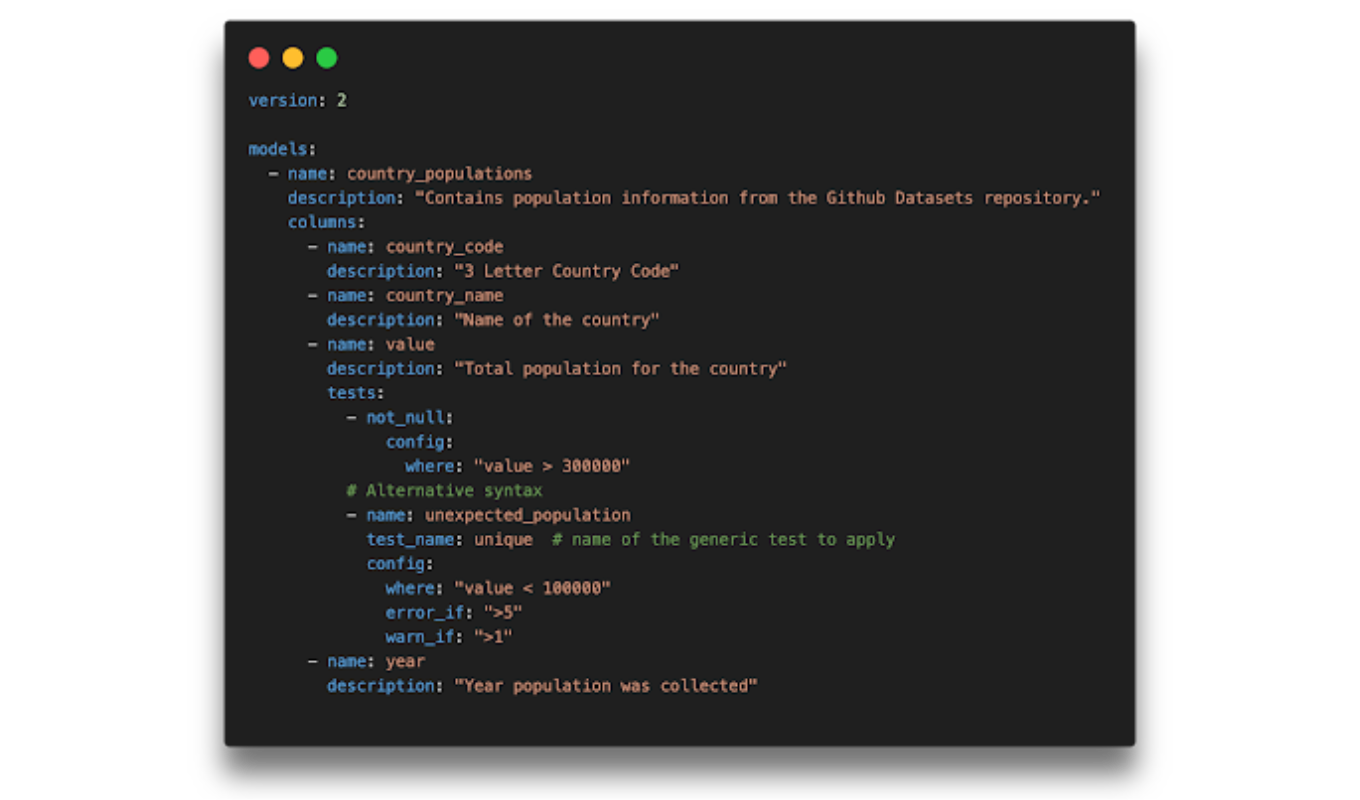
dbt test configuration example. Source: https://datacoves.com/post/dbt-test-options
To ensure adoption and ease of use, we designed the framework with YAML configuration files at its core. This design choice was critical. At the time, the client’s team possessed deep domain knowledge but lacked extensive experience with testing tools, such as pytest. They needed an intuitive interface to define test cases without navigating the complexities of a full software testing suite.
Our solution consists of three robust modules:
- Config Validator: Leverages marshmallow to strictly validate configuration models, ensuring integrity before execution.
- Snowflake Account Connector: Utilizes Snowpark and boto3 for secure secret fetching and connection management.
- Test Runner: Built on pytest with pytest-subtests to orchestrate execution efficiently.
Simplifying Test Definitions
The setup enables developers to create any number of test configuration files under a directory structure that suits their workflow. During execution, the framework crawls these files recursively, ensuring comprehensive coverage.
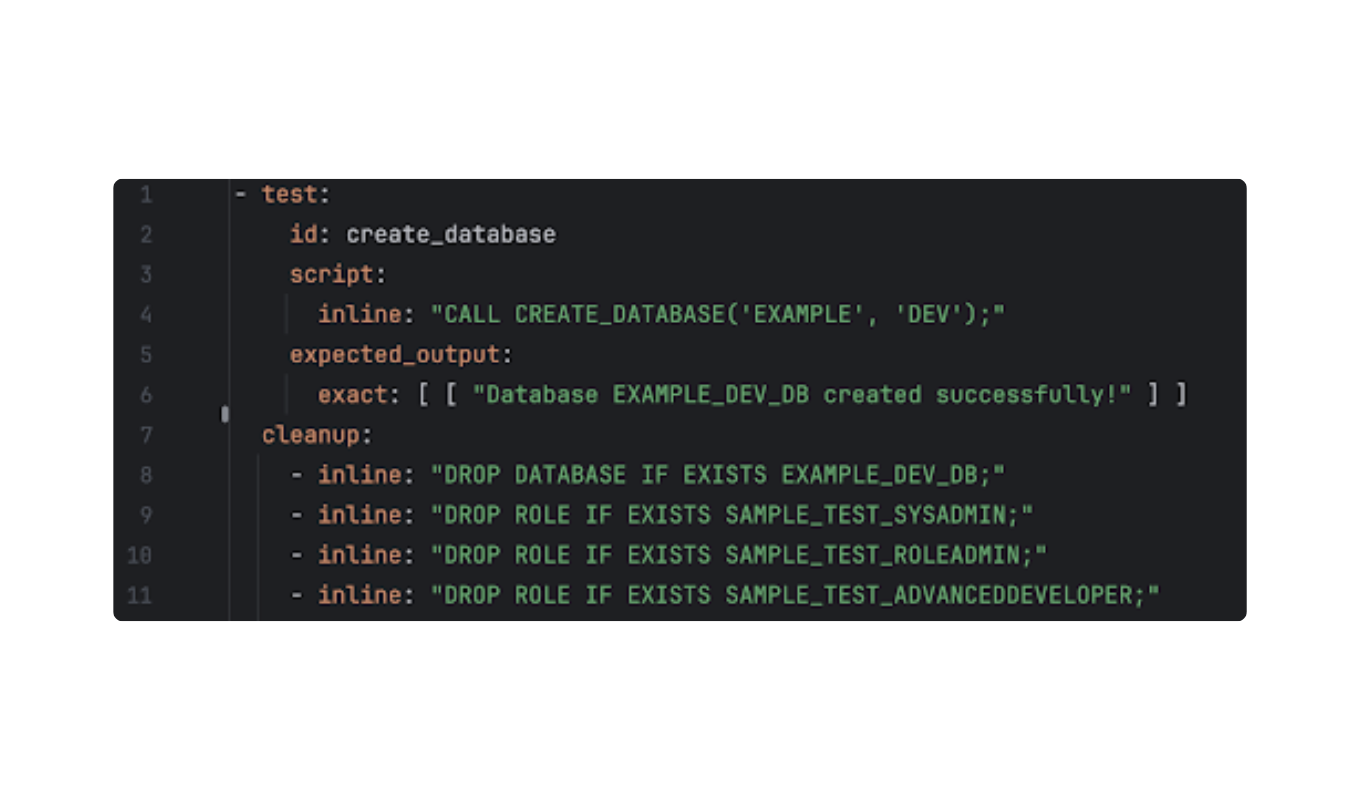
Simple config example in our framework. Source: Unit8
Each test unit is structured to ensure clarity and reliability:
- SQL Script: The exact command or logic to be tested (e.g., CALL CREATE_DATABASE).
- Expected Output: Defined as a list of rows (aligning with how Snowpark returns query outputs) to validate the immediate result.
Cleanup Scripts: A list of commands executed post-test to tear down resources, ensuring the environment remains pristine.
Advanced Validation Capabilities
Since real-world infrastructure is rarely simple, our framework is designed to support advanced scenarios that go beyond basic script execution.
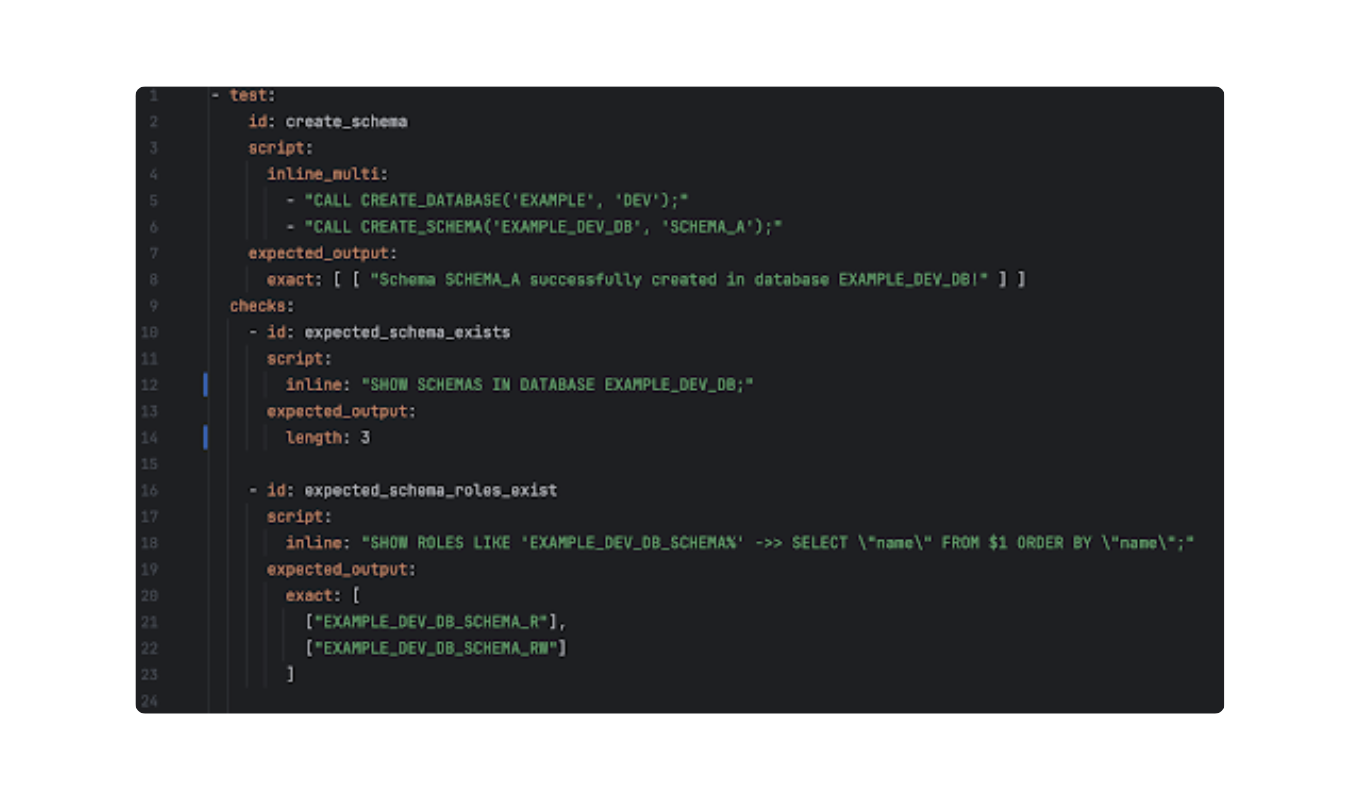
Config example with checks in our framework. Source: Unit8
In more complex use cases, the framework delivers additional value:
- Multi-line Script Support: It can process complex blocks of code, evaluating the output of the final command against expectations.
- Post-Execution State Checks: This is a critical feature for infrastructure testing. Stored procedures often return a simple “Success” message, which is insufficient for verifying that a schema or role was actually created. Our framework allows users to define multiple checks (e.g., running SHOW SCHEMAS) after the main test.
- Flexible Assertions: Beyond exact matching, the framework supports checking for specific row counts (e.g., length: 3), regular expression matches, or even expected error messages.
Scalability Through Parametrization
To support the platform as it scales, we introduced features that adhere to the “Don’t Repeat Yourself” (DRY) principle.
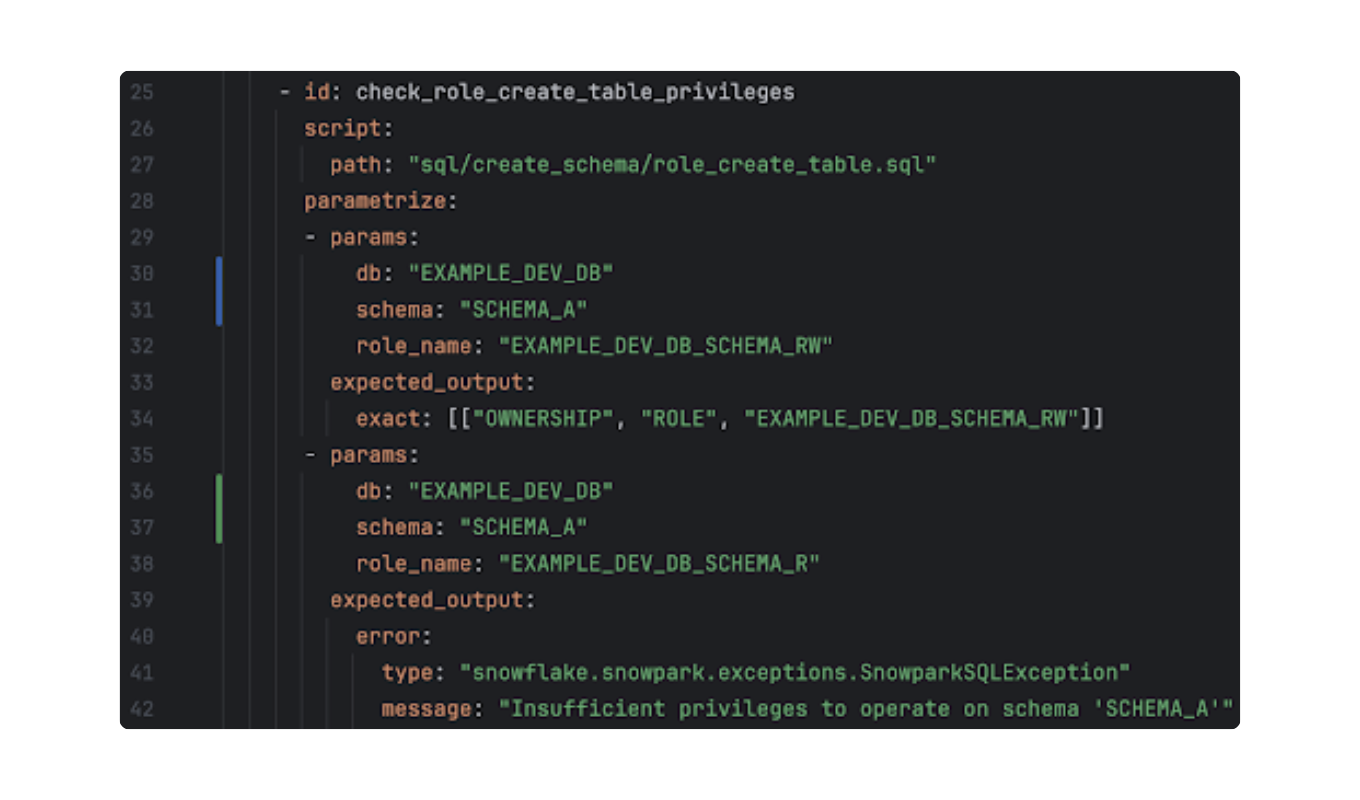
Parametrized check example in our framework. Source: Unit8
Two key features enhance the scalability of the tests:
- External SQL Files: Instead of writing inline scripts, developers can pass a path to a SQL file (e.g., sql/create_schema/role_create_table.sql). This keeps the YAML configuration clean and allows for better version control of the SQL logic.
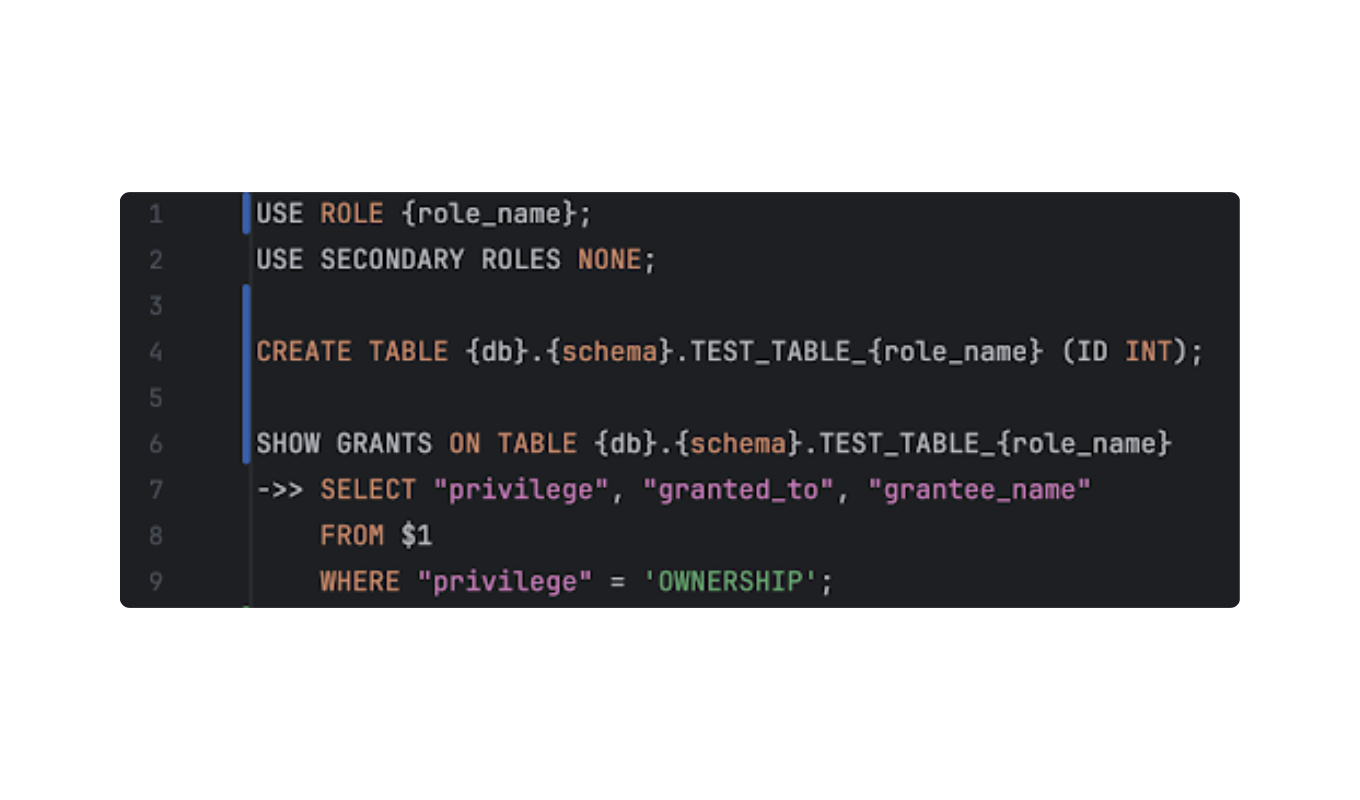
- Parametrization: If a script contains standard Python formatting placeholders (like {role_name}), the framework can iterate through a list of parameters. It invokes the same SQL script with different inputs for each pass, evaluating the results, whether success or expected error, independently. This allows a single test definition to validate dozens of infrastructure scenarios.
Conclusion
Automating infrastructure testing is no longer a luxury; it is a necessity for maintaining reliable, compliant, and scalable data platforms. This solution enabled both our team and the client to define reliable tests for end-user provisioning procedures, significantly reducing manual overhead.
While we continue to refine the framework, exploring features such as local environment execution and automatic resource detection, this lightweight approach has already proven to be a vital asset. It empowers the client to maintain high velocity in their development cycle without compromising the security or stability of their Snowflake environment.
