
- Apr 20, 2023
- 12 minutes
Written By
In today’s data-driven world, organizations are generating large amounts of data from various sources, including Internet of Things (IoT) devices. This data contains valuable insights that can help businesses and customers make informed decisions and improve their operations. However, managing and processing this data in real-time can be a challenging task. In this article, we will explore an AWS based Data Warehouse, i.e. a cloud-based data storage and analytics solution that enables businesses to store, process, and analyze large amounts of data from various sources, including IoT devices, in real-time. To accomplish this, we study a specific use case and we will design an AWS infrastructure that will accommodate its requirements while also making our approach generalizable. Finally, we provide the code that deploys our Data Warehouse on AWS in this GitHub repository.
The preceding use case was implemented using AWS infrastructure; however, it is transferable to other public cloud providers. To illustrate, with Microsoft Azure, we can leverage Microsoft Azure Stream Analytics, Microsoft Azure Synapse Analytics, and Azure Cache for Redis. Alternatively, on Google Cloud Platform, we can utilize Google Cloud Dataflow, Google Cloud BigQuery, and Google Cloud Memorystore for comparable outcomes. It is imperative to note that regardless of the chosen public cloud provider, it is vital to assess the compatibility of the proposed solution with the platform’s infrastructure and services. Therefore, it is recommended to engage with a cloud solutions expert to evaluate and determine the most suitable cloud provider and services for your business requirements.
Use Case
The example use case we will study is a company in the field of Precision Agriculture that utilizes IoT devices to provide analytics and recommendations to its customers. The devices record data every 5 seconds and send it over the internet for storage and analytics purposes. This raises the need for a scalable solution that accepts the onboarding of new IoT devices over time and provides the customers with measurements and analytics to improve their crops. The device measurements need to be immediately accessible through a mobile device. The analytics can be accessed as time passes and more data are acquired, without any urgent need to be immediately available.
Architecture
To meet the aforementioned requirements, our solution should be fully managed, scalable, secure, and performant for specific use cases while maintaining a low cost. It should also provide analytics and insights from the stored data without much overhead. Therefore, the architecture of the Data Warehouse should include an entry point for the real-time data, a storage space for immediate retrieval of recent data, a data warehouse space for all data, and analytics functionality for quick data insights. The AWS architecture we designed to meet all these requirements is presented below.
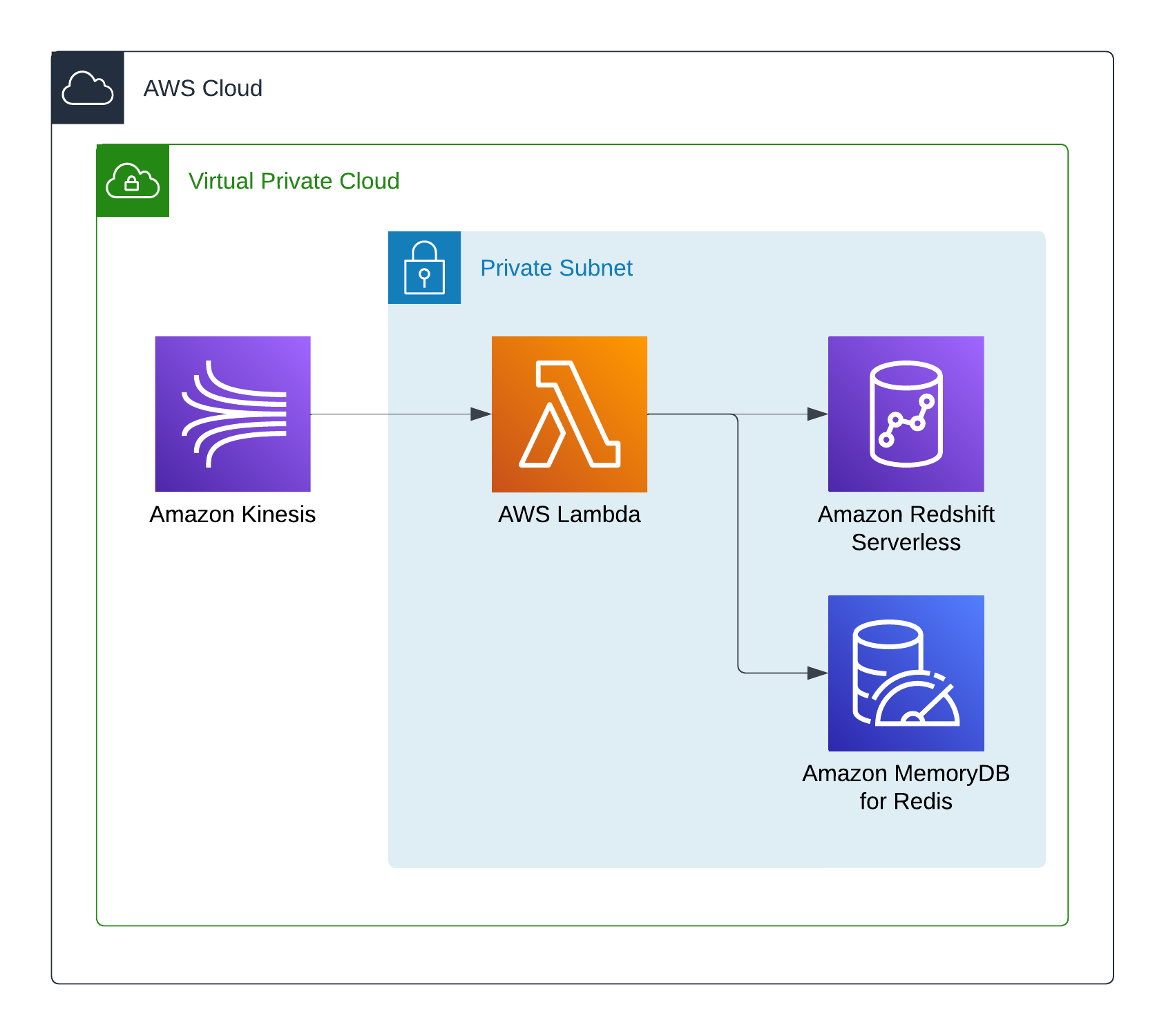
The entry point to our architecture is a Kinesis Data Stream, which collects real-time data from various sources and, in our case, IoT devices. The time series data is processed by a Lambda application which is triggered by the incoming data from Kinesis in batches of 100 records. The ingestion application stores the last 7 days of time series data in a Redis cluster on Amazon MemoryDB for ultra-fast retrieval and all incoming data in an Amazon Redshift Serverless database that acts as our data warehouse for long-term storage, data analytics, and data insights.
We ensure the security of our architecture with various measures, such as limited ingress rules in security groups and by setting up the AWS Lambda, Amazon MemoryDB, and Amazon Redshift Serverless services inside the private subnets of our VPC. The incoming data traffic to Kinesis through the internet will be encrypted and after its arrival, it never leaves the VPC.
The scalability of our application is ensured by the utilization of fully managed AWS services that incorporate the serverless architecture. The Kinesis Data Stream scales on demand or by provisioning the number of computing shards in steady loads. The Lambda function can withstand workloads of at least 50,000 incoming Kinesis records per second. The MemoryDB cluster can add more nodes to balance increasing data traffic, and the Redshift Serverless database scales its capacity and compute performance automatically.
Of course, we acknowledge the fact that AWS Lambda can be a throttling point in case of vast data loads. However, in the case we are studying, the IoT devices send over 1 record per 5 seconds, a load that Lambda is more than capable of handling. In case our requirements specified huge workloads, we could easily refactor our ingestion Lambda application to run on an ECS cluster using the Kinesis Consumer Library to consume records from Kinesis. This would allow the ingestion application to scale a lot better and accommodate big data workloads. It is important to note that the architecture of our ingestion application facilitates refactoring through the utilization of the separation of concerns principle.
Finally, it is worth noting that our architecture can be easily extended in case our requirements specify the need for instant retrieval of aggregated data. For example, we could add an extra layer that includes an application that retrieves aggregated data from the Redshift database by querying them using aggregate functions as soon as they are stored. The aggregated data could afterwards be stored in a new MemoryDB cluster for ultra fast retrieval. Of course, this would increase the cost of the solution.
Amazon Kinesis
Amazon Kinesis is a fully managed service on AWS that allows ingestion of real-time data such as IoT telemetry data, audio, video, and more for Machine Learning, analytics, and other applications. Kinesis is able to receive data in real time from various sources using the AWS SDK for Java and the Kinesis Producer Library. In our case, we utilize an Amazon Kinesis Data Stream (KDS) to collect real time data from the IoT devices for processing and storage in our data warehouse.
In our solution, the stream’s capacity mode is set to on demand. While it is more expensive than provisioned capacity, it facilitates the scaling of the stream in cases of inconsistent load. If devices are slowly onboarded to the data warehouse, the wisest move is to wait until the load is stabilized. Then the stream’s capacity mode can change to provisioned with a specific number of computing shards for cost reduction. For fluctuations in the load after switching to the provisioned mode, this official AWS blog post provides a custom solution for autoscaling the Kinesis Data Stream shards using CloudWatch Alarms and AWS Lambda.
resource "aws_kinesis_stream" "data_warehouse_stream" { name = "data-warehouse-stream" retention_period = 72 shard_level_metrics = [ "IncomingBytes", "IncomingRecords", "OutgoingBytes", "OutgoingRecords", "IteratorAgeMilliseconds" ] stream_mode_details { stream_mode = "ON_DEMAND" } }
To ensure that the data warehouse is functioning properly, it is important to monitor the Kinesis Data Stream’s metrics, especially the IncomingRecords, IncomingBytes and GetRecords.IteratorAgeMilliseconds metrics. By monitoring IncomingRecords and IncomingBytes we can prevent any possible extended data losses since fluctuations in those metrics can mean that the data we receive is lower or higher than the baseline for our load. In addition, an increase in the GetRecords.IteratorAgeMilliseconds metric indicates that our ingestion application cannot keep up with the data load and that data is not immediately stored. As a result, our data warehouse lags behind. A value of zero indicates that data are stored as soon as they arrive at the Kinesis stream.
AWS Lambda
AWS Lambda’s integration with Amazon Kinesis makes it easy to ingest data to various targets. A function may use a Kinesis Data Stream as a trigger event source and can process 100 records per invocation. The default parallelization parameter of Lambda invocations per Kinesis stream shard is 1. However, this can be increased so that multiple concurrent Lambdas can process batches of Kinesis records from 1 shard.
The ingestion Lambda application is written in Python and makes use of various best practices to ensure the future extendability of the ingestion targets to additional or replacement services. The Lambda handler is decoupled from the connection to the Amazon MemoryDB and Amazon Redshift Serverless targets, while also including as little logic as possible to avoid over-complication. The MemoryDB class contains a function that ingests the time series data to Redis as lexicographic sorted sets according to the official best practices guide. The Redshift class contains a function that checks if the target database table exists, a function that creates the table and its columns if it doesn’t, and a function that ingests the time series data to the table.
The ingestion Lambda application is deployed using Terraform inside the VPC and its private subnets to enhance security, while also using a security group with no ingress rules. The function utilizes the Python 3.9 runtime and its available memory is the lowest possible, 128MB. Its event source trigger is the aforementioned Kinesis Data Stream and the function requires an IAM role for permissions to write logs to CloudWatch and access the VPC, Kinesis, and Redshift services.
resource "aws_lambda_function" "data_warehouse_ingestion_lambda" { filename = "data_warehouse_ingestion_lambda.zip" function_name = "data-warehouse-ingestion-lambda" handler = "main.handler" role = aws_iam_role.data_warehouse_ingestion_lambda_role.arn runtime = "python3.9" memory_size = 128 source_code_hash = data.archive_file.data_warehouse_ingestion_lambda_zip.output_base64sha256 vpc_config { security_group_ids = [aws_security_group.data_warehouse_ingestion_lambda_sg.id] subnet_ids = var.private_subnet_ids } environment { variables = { MEMORYDB_HOST = aws_memorydb_cluster.data_warehouse_memorydb.cluster_endpoint[0].address REDSHIFT_WORKGROUP_NAME = aws_redshiftserverless_workgroup.data_warehouse_redshift_workgroup.id REDSHIFT_DATABASE_NAME = aws_redshiftserverless_namespace.data_warehouse_redshift_namespace.db_name REDSHIFT_TABLE_NAME = var.redshift_table_name } } } resource "aws_lambda_event_source_mapping" "data_warehouse_ingestion_lambda_event_source" { event_source_arn = aws_kinesis_stream.data_warehouse_stream.arn function_name = aws_lambda_function.data_warehouse_ingestion_lambda.arn starting_position = "LATEST" }
resource "aws_iam_role" "data_warehouse_ingestion_lambda_role" { name = "data-warehouse-ingestion-lambda-role" assume_role_policy = data.aws_iam_policy_document.assume_role.json inline_policy { name = "data-warehouse-ingestion-lambda-inline-policy" policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "ec2:DescribeNetworkInterfaces", "ec2:CreateNetworkInterface", "ec2:DeleteNetworkInterface", "ec2:DescribeInstances", "ec2:AttachNetworkInterface", "ec2:AssignPrivateIpAddresses", "ec2:UnassignPrivateIpAddresses", "kinesis:GetRecords", "kinesis:GetShardIterator", "kinesis:DescribeStream", "kinesis:ListShards", "kinesis:ListStreams", "redshift-serverless:GetCredentials", "redshift-data:ExecuteStatement", "redshift-data:ListDatabases", "redshift-data:ListSchemas", "redshift-data:ListTables", ] Effect = "Allow" Resource = "*" }, ] }) } }
Amazon MemoryDB for Redis
Amazon MemoryDB for Redis is a fully managed, Redis-compatible, in-memory database that delivers ultra fast performance. In our architecture, it acts as a storage for recent data for which immediate access is required. The IoT measurement time series are stored in this Redis database as a lexicographic sorted set. In short, we aggregate the timestamps and the values of the time series under a key, which is the ID of the IoT device. For example, when querying a specific IoT device ID, the returned result would have the timestamp on the left and the value on the right separated by a colon symbol.
1) 1679321000:1.045
2) 1679321005:0.678
3) 1679321010:0.345
4) 1679321015:0.287
5) 1679321020:0.264
A better alternative to this approach would be to utilize the TimeSeries Redis module to store time series data on a Redis database and aggregate them on the fly using its aggregation functions. However, Redis modules are not supported by Amazon MemoryDB for Redis or Amazon ElastiCache. In order to simplify our architecture by only using fully managed AWS services, we opted for using only the core feature of Redis provided by Amazon MemoryDB.
We set the MemoryDB cluster to utilize a db.r6g.large node type and 1 shard for our PoC. We set the data retention to 7 days as we are required to only retain the last week of data. To maximize security, we placed the cluster in the private subnets to VPC and we configured its security group to only accept traffic originating from the security group of the ingestion Lambda application.
resource "aws_memorydb_subnet_group" "data_warehouse_memorydb_subnet_group" { name = "data-warehouse-memorydb-subnet-group" subnet_ids = var.private_subnet_ids } resource "aws_memorydb_cluster" "data_warehouse_memorydb" { acl_name = "open-access" name = "data-warehouse-memorydb" node_type = "db.r6g.large" security_group_ids = [aws_security_group.data_warehouse_memorydb_sg.id] subnet_group_name = aws_memorydb_subnet_group.data_warehouse_memorydb_subnet_group.id num_shards = 1 snapshot_retention_limit = 7 }
Amazon Redshift Serverless
Amazon Redshift Serverless is a fully managed data warehouse service on AWS that can perform real-time or predictive analytics to get insights from data as soon as they are stored. It scales automatically and delivers fast performance even in demanding or unpredictable workloads. Due to its serverless nature, it is also cost-effective, as customers pay only for the resources they use.
We utilize Redshift Serverless as our data warehouse by creating a namespace, which defines a logical container for database objects, and a workgroup associated with it. In the workgroup, we create a generic database and table for all data in the data warehouse. That is to make our solution as less specific as possible and provide means for its extension.
To ensure the security of the data warehouse, we deploy the workgroup inside the VPC and its private subnets making it available only inside the VPC. Since our data traffic should not pass through the internet, we have made the workgroup inaccessible publicly and have not created a NAT gateway in our VPC. Instead, we have created an Interface VPC Endpoint for the Redshift Data endpoint so that all traffic passes through it in order to reach the database. It is also important to note that enhanced VPC routing must be enabled in the workgroup so that it utilizes the VPC’s network. Finally, we have allowed access to the workgroup only from the security group of the ingestion Lambda application. Additional rules can be added in the future to accommodate the use of APIs that query the data warehouse.
resource "aws_vpc_endpoint" "redshift_data_interface_vpc_endpoint" { vpc_id = aws_vpc.vpc.id service_name = "com.amazonaws.eu-central-1.redshift-data" vpc_endpoint_type = "Interface" subnet_ids = [aws_subnet.private_subnet_a.id, aws_subnet.private_subnet_b.id, aws_subnet.private_subnet_c.id] private_dns_enabled = true }
resource "aws_redshiftserverless_workgroup" "data_warehouse_redshift_workgroup" { namespace_name = aws_redshiftserverless_namespace.data_warehouse_redshift_namespace.namespace_name workgroup_name = "data-warehouse-workgroup" enhanced_vpc_routing = true publicly_accessible = false subnet_ids = var.private_subnet_ids security_group_ids = [aws_security_group.data_warehouse_redshift_sg.id] }
At this point a very good question may come to the reader’s mind. Why didn’t we utilize Kinesis Firehose to directly store incoming records to Redshift Serverless? Unfortunately, at the moment of writing, this is only possible in case the workgroup is publicly accessible. Something that would compromise the security of our solution. Therefore, we chose to develop a custom application for the storage of data in our Redshift Serverless workgroup and maintain its privacy.
Business Value
Data warehouses on AWS provide a highly scalable and cost-effective solution for storing and analyzing IoT real-time data. By leveraging AWS’s cloud-based infrastructure and services, businesses can easily manage and process large volumes of IoT data in real-time. This allows businesses to derive valuable insights and make informed decisions quickly, leading to improved operational efficiency, enhanced customer experiences, and increased revenue. Additionally, AWS offers a variety of tools and services for data warehouses, such as Amazon Kinesis for real-time data processing and Amazon Redshift which provides powerful analytics capabilities. Overall, data warehouses are an essential component for businesses looking to leverage IoT data to gain a competitive advantage.
In this article we explored a Data Warehouse solution on AWS to meet the requirements of a specific use case while also making our approach general enough to accept extensions and modifications. We ensure that our infrastructure is secure, performant, and scalable by utilizing AWS managed services and the AWS Well-Architected framework.

