
- Dec 16, 2024
- 10 minutes
Written By
-
 Michal Rachtan
Michal Rachtan
In the rapidly evolving landscape of artificial intelligence, control over data privacy, sovereignty, and the infrastructure hosting AI models has become paramount for many enterprises. NVIDIA has emerged as a key enabler in this space, shipping the best-in-class computing infrastructure, including GPUs and servers specifically designed for large language model (LLMs) training and inference. Their cutting-edge hardware, such as the H100 GPUs, is complemented by a robust suite of software solutions that significantly lower the entry barrier for companies looking to harness the power of AI.
Until recently, organizations seeking frontier AI models had limited options and often had to rely on black-box intelligence providers. With open-source models rapidly becoming as capable as leading proprietary models, achieving parity in terms of performance, businesses now have more choices. For those requiring flexibility and full control over their models and data, NVIDIA’s AI Enterprise software suite presents a strong alternative. By integrating seamlessly with existing applications, it offers a platform to develop, deploy, and manage LLM-based applications while addressing compliance needs. Its pre-trained models and optimized inference processes make it a practical choice for maximizing the potential of enterprise AI.
Here's how NVIDIA empowers Enterprise AI:
- NVIDIA AI Enterprise: A software suite that integrates with VMware Cloud Foundation, allowing secure running of AI workloads alongside existing enterprise applications. This suite includes TensorRT-LLM (SDK) and NeMo, providing a comprehensive platform for developing, deploying, and managing LLM-based applications in enterprise environments.
- NVIDIA AI Foundation Models: These pre-trained models offer a robust starting point for various AI tasks, covering applications like natural language processing and computer vision. Optimized for NVIDIA hardware, they provide a drop-in replacement for black-box solutions in various AI applications.
- NVIDIA NeMo: A comprehensive framework for building and training custom LLMs across various platforms. NeMo offers a range of customization techniques, from prompt learning to parameter-efficient fine-tuning, enabling developers to create and optimize LLMs for specific use cases.
- NVIDIA NIM (Inference Microservices): NIM streamlines AI model deployment with GPU-accelerated microservices. Containerized deployment, TensorRT optimization, and broad model support simplify the process and enhance efficiency.
- NeMo Retriever – Optimized RAG text embedding: A collection of inference microservices (NIMs) designed for text embedding and reranking in retrieval-augmented generation (RAG) pipelines.
- NeMo Customizer – Scalable LLM fine-tuning: A high-performance microservice designed to simplify the fine-tuning and alignment of Large Language Models (LLMs) for domain-specific use cases. It supports several parameter-efficient fine-tuning (PEFT) techniques.
- NeMo Guardrails: An open-source toolkit ensuring generative AI applications are accurate, appropriate, and safe.
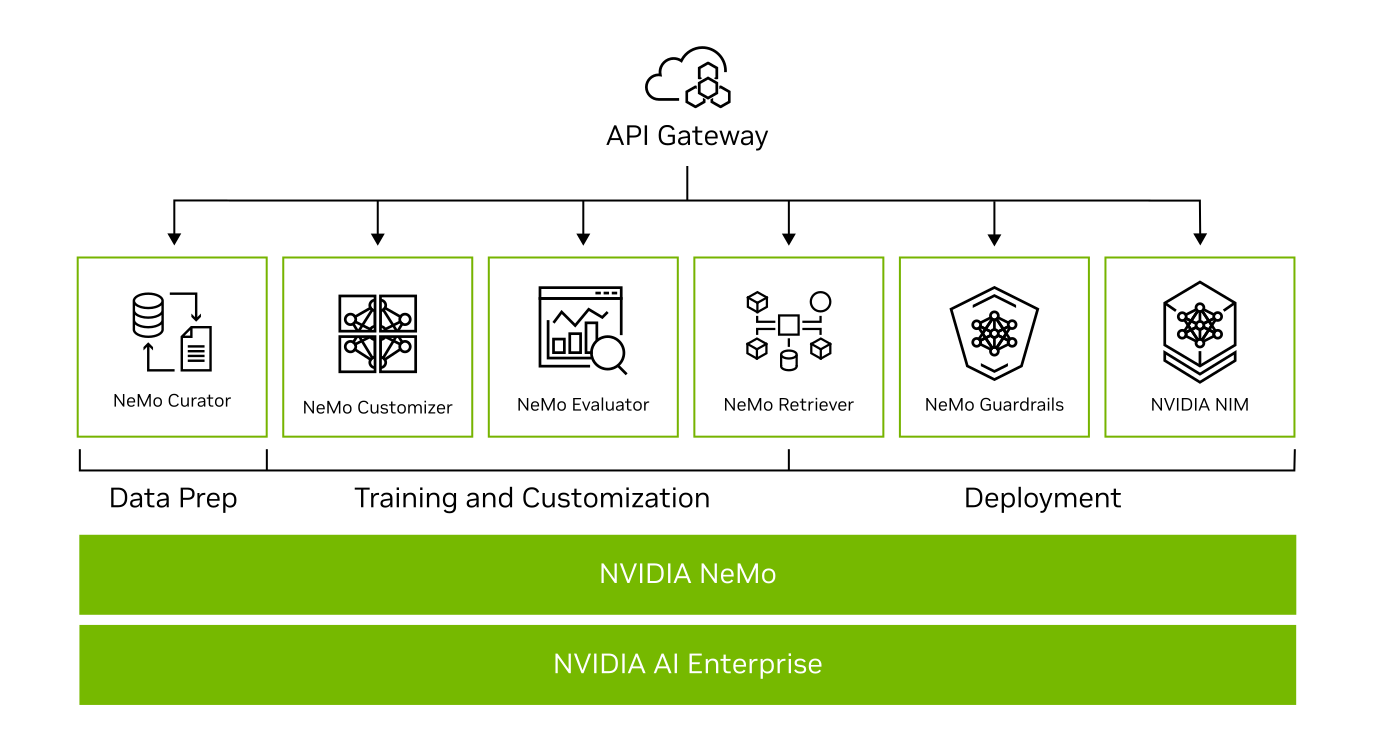
Full range on NVIDIA NeMo tools. Source: https://www.nvidia.com/en-us/ai-data-science/products/nemo/
By combining hardware and software, NVIDIA provides a solution that works as well on the cloud as in a data centre. It could be a viable choice for companies looking to make the most out of cloud and on-premise hardware.
Unit8's GenAI HyperScaler further enhances NVIDIA's capabilities:
Unit8’s GenAI HyperScaler provides a secure and flexible solution for companies looking to adopt generative AI. It allows for the deployment of a fully client-owned AI stack on your existing cloud subscriptions or on-premise, ensuring data security with a private network. This approach, combined with the flexibility to use any supported open-source Large Language Model (LLM), empowers businesses to tailor their AI solutions to specific needs and compliance requirements.
The integration of HyperScaler with NVIDIA NIM further enhances this offering. By enabling the use of any supported open-source LLM within a secure environment, it allows organizations to leverage the power of advanced AI while maintaining complete control over their data and infrastructure. This combination of security, flexibility, and control makes HyperScaler a compelling solution for businesses seeking to accelerate their AI adoption journey.
Key benefits of this combined approach:
- Data Privacy and Sovereignty: Maintain complete control over your sensitive data.
- Infrastructure Control: Host your AI models where you want, how you want.
- Flexibility: Customize and adapt LLMs to your specific needs.
- Security: Deploy in a secure environment, even within your existing cloud subscriptions.
- Efficiency: Optimize performance with NVIDIA’s hardware and software solutions.
By combining the power of NVIDIA’s AI ecosystem with the security and flexibility of Unit8’s GenAI HyperScaler, organizations can unlock the full potential of LLMs while maintaining the highest levels of data privacy, sovereignty, and control.



