
- Jul 2, 2021
- 15 min read
Written By
- Julien Herzen
In this post, we will explore a fascinating emerging topic, which is that of using reinforcement learning to solve combinatorial optimization problems on graphs. We will see how this can be done concretely for finding solutions to the celebrated Traveling Salesman Problem. Our approach will combine neural networks that learn embeddings of random graphs and reinforcement learning to iteratively build solutions. In the end, we will obtain a single neural network that will be able to produce relevant routing decisions on new random graphs.
We will build a solution iteratively throughout the article, using Python and PyTorch.
Traveling Salesmen and Pub Crawls
The Traveling Salesman Problem (TSP) consists in finding the shortest possible tour connecting a list of cities, given the matrix of distances between these cities. Here is an example of a solution (from the Wikipedia TSP article [1]):
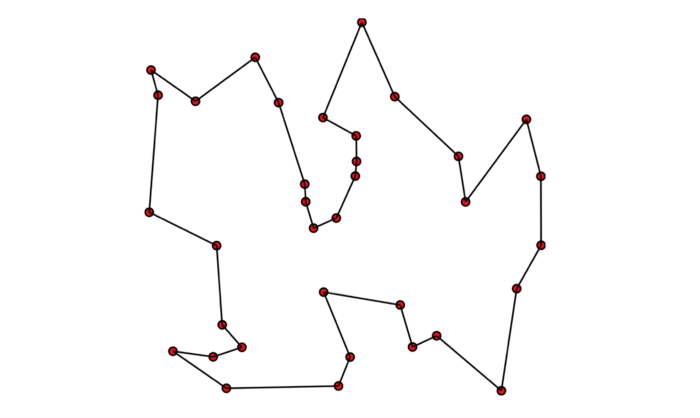
This problem has many very concrete applications in domains such as logistics, vehicle routing, chip manufacturing, astronomy, image processing, DNA sequencing and more.
It is known that finding an optimal solution is a NP-hard problem — and there exists N! different possible ways to assemble a tour visiting N cities. Despite these gloom prospects, the problem has a very rich history, and it has been one of the most studied problems of computational sciences. There now exists a host of different techniques — both exact and heuristics — to find good solutions efficiently. The approaches range from simulating ant colonies heuristics, to extremely efficient solvers (such as Concorde [2]) making sophisticated use of integer linear programming methods to find exact solutions.
Solvers such as Concorde can find optimal tours for problems of a few tens of thousands of cities, and close-to-optimal (within 1% or less) tours for problems with millions of cities. At the time of writing, one of the largest problem instance was solved using Concorde in 2006, and it involved 85,900 interconnections (“cities”) on a VLSI application, which at the time took 136 CPU-years [1]. This instance of the problem was Euclidean — meaning that all the distances between the cities are the Euclidean distances between them. Large non-Euclidean problems (for instance, such as considering walking times between cities instead of Euclidean distances) have also been solved, although this is in general much more challenging.
Maybe the most important instance ever solved consists in a tour going through 49,687 pubs in the UK with the smallest walking distance (45,495,239 meters). It was computed in March 2018 [3]:
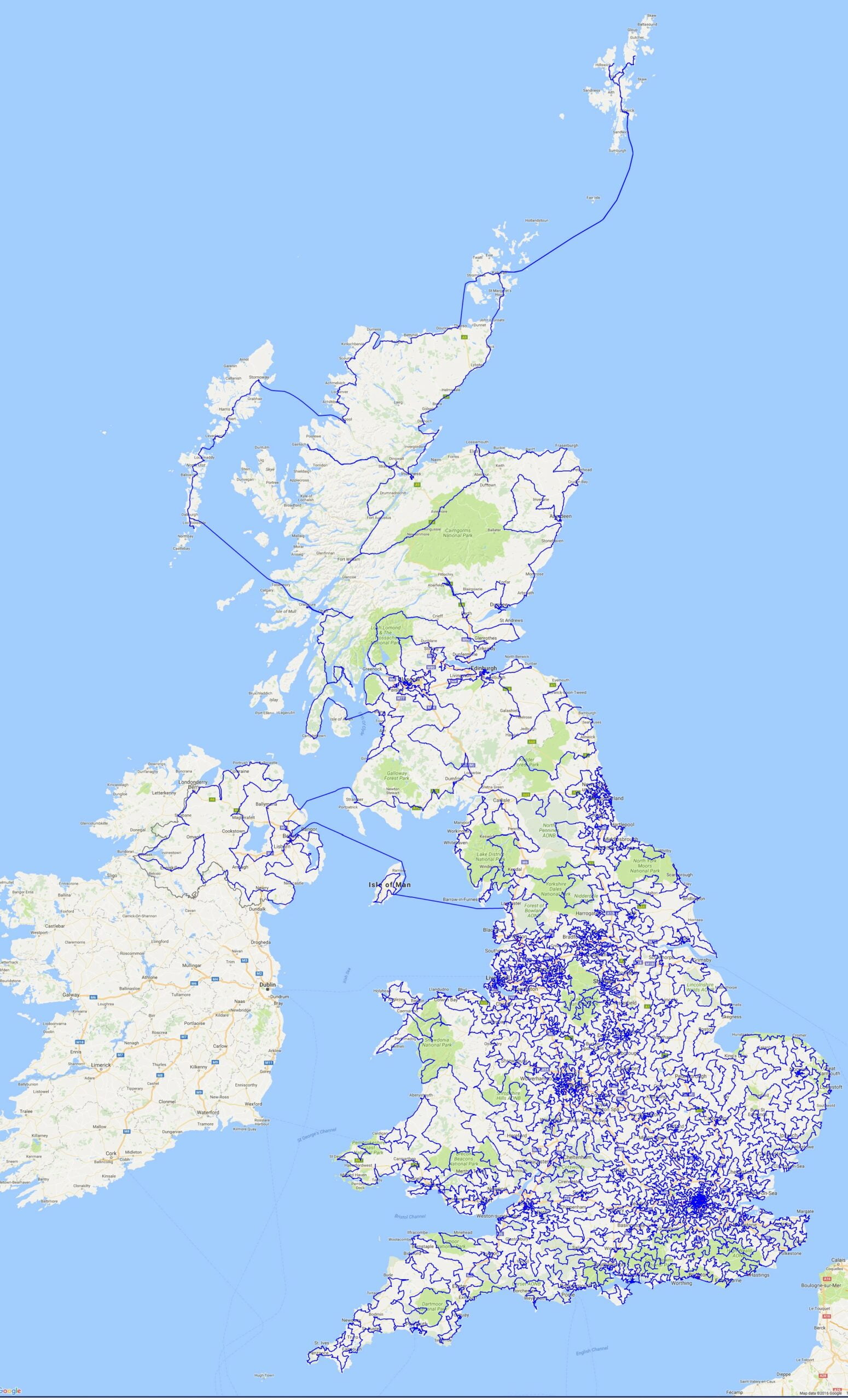
Overall, we recommend the interested readers to consult [4] for more information and nice anecdotes about the TSP problem, its history, and how it is solved in practice today.
Why Reinforcement Learning?
In this post, we will try a completely different way to approach the TSP problem, using reinforcement learning. But why would we even do that, given that there already exists a host of very effective techniques for solving the TSP?
Here, our goal isn’t to beat current solvers — in fact we won’t even come close. Rather, we will consider a different point in the tradeoff space: We will build a neural-network that finds tours without any built-in knowledge of the TSP. The only signals used by our model will be the observed cumulative “rewards” — that is, how long some tours (or portions of tour) are. There is a very elegant side to this approach, as it means that the algorithm can potentially figure out the problem structure without human help.
Having the computer figure out good heuristics by itself is perhaps the most common dream of computer scientists.
In addition, the approach has a couple of other advantages:
- It’s possible to easily plug in fairly arbitrary reward functions in this framework, so one can use the exact same algorithm on different variants of the TSP, and notably on variants that significantly deviate from being Euclidean. Think for instance of minimizing a tour duration, with some time being spent in each city, or with random delays attached to links and depending on certain dynamic features.
- Inference speed & online use: once we’ll have trained our neural network to output the next best city to visit, this means that deciding where to go next just requires a forward pass through our network, which is typically very fast. It thus lends itself better to dynamic and online use-cases than some slower approaches.
- We get to apply some machine learning on yet another problem. It’s 2020 after all!
In this post, we will only consider toy problems (nothing like the pub crawl one showed above), and focus on building the full solution end-to-end in a comprehensible way, rather than on getting amazing performance.
