
- Sep 26, 2024
- 7 minutes
Written By
In the journey toward adopting on-premise generative AI, after understanding its benefits and preparing for implementation, the next crucial step is designing the right architecture for scalable and efficient deployments. Large Language Models (LLMs), along with most modern machine learning workloads, run most efficiently on GPUs. This is because LLMs are Artificial Neural Networks, which demand extensive parallel processing capabilities that GPUs are specifically designed to handle.
Hardware requirements
There are numerous vendors and platforms offering GPU-equipped servers, but Nvidia stands out with the most comprehensive solution. NVIDIA DGX servers are purpose-built for enterprise AI, integrating Nvidia’s cutting-edge hardware, software, and expertise. When combined with the NVIDIA AI Enterprise software platform, they deliver a fully optimized, end-to-end solution designed to meet the demands of modern AI workloads.
When planning for hardware capacity before placing orders, it’s essential to account for several factors. While this isn’t an exhaustive guide, it highlights the key considerations. The most critical aspect is LLM serving. Review the documentation of both your chosen LLM and serving platform to determine the number of GPUs required to serve your model and the number of deployment instances needed to achieve your desired throughput. If you’re considering fine-tuning (as discussed in Part 2 of this GenAI series, and something you should strongly consider), allocate sufficient GPUs for running experiments and final training. Keep in mind that LLM training demands significantly more aggregated GPU memory than serving, so plan your resources accordingly. Additionally, if you’re deploying custom models, factor in the need for a testing environment alongside your live setup to validate models before going live.
Orchestration requirements
Having the right hardware to run LLMs is essential, but it’s equally important that your orchestration platform can effectively pass GPUs to the application runtime. There are two main approaches for this.
The first is virtualization, a well-established and reliable method. Most hypervisor vendors support GPU passthrough to virtual machines, allowing DevOps teams to manage deployments within the guest operating system.
The second, more modern approach is containerization. Container runtimes have quickly evolved to support GPU orchestration, offering both runtime and orchestration capabilities. Organizations can manage LLM deployments in containers just like any other web application. Given the agility required for executing fine-tuning workloads, deploying models, scaling and adapting to increased user demand, containerization is often the preferred option for such dynamic environments.
Early-stage architecture
In the early stages of developing GenAI applications, a single inference server can efficiently support multiple applications simultaneously. Modern data center GPUs have ample power to handle such tasks, providing a robust foundation for scalable AI deployments. In the most common configuration, a single server unit can handle 8 GPUs leaving enough PCI-express bandwidth for common peripherals. For instance, a cluster of eight Nvidia H100 GPUs can process up to 762 tokens per second with the LLama2 70B model, illustrating the high capacity available for distribution across various applications [1].
Switching to open-source LLMs deployed on a GPU-equipped server(s) is straightforward for the application developers. By using an LLM server that has an OpenAI-compatible endpoint (e.g.: Nvidia NIM, vLLM), these models can serve as seamless drop-in replacements for applications currently utilizing ChatGPT. This flexibility allows developers to experiment with different models and configurations without disrupting existing workflows, fostering innovation and adaptability.
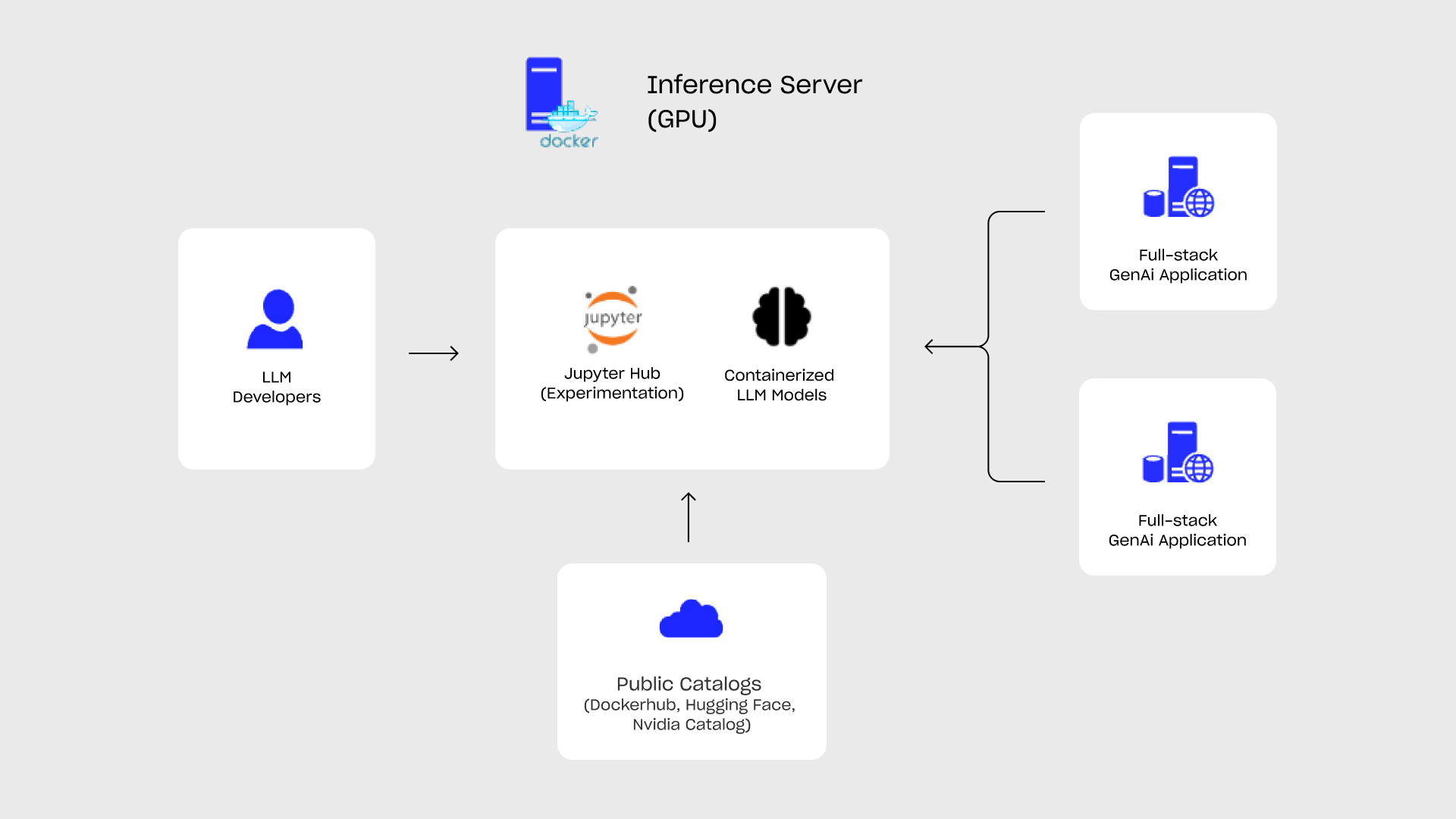
Fig 2.: Single node GenAI deployment with Docker
For small-scale operations, Docker as an orchestration platform is the perfect compromise between complexity and manageability. With NVIDIA Container Toolkit it has native support for GPUs. For initial application, multiple vendors are shipping production-ready containerized LLMs (e.g.: Nvidia NIMs), but packing and building new production-ready containers using open-source software (e.g.: vLLM) is fairly well documented and simple.
In addition, remote developer sandbox environments can be deployed to the server (e.g: Jupyter hub) to open up the left-over resources for experimentation. Containerization guarantees isolation from production workloads.
For small-to-medium-scale Retrieval-Augmented Generation (RAG) applications, integrating an in-process vector database and a web server directly into the application server can streamline operations. This approach reduces complexity on the application side, enabling teams to manage and deploy multiple versions efficiently. Development, testing, and production environments can be maintained with ease, promoting a smoother and more organized workflow.
Scale-out phase
As GenAI use cases grow and demand surpasses the capacity of a single server, more robust infrastructure becomes essential.
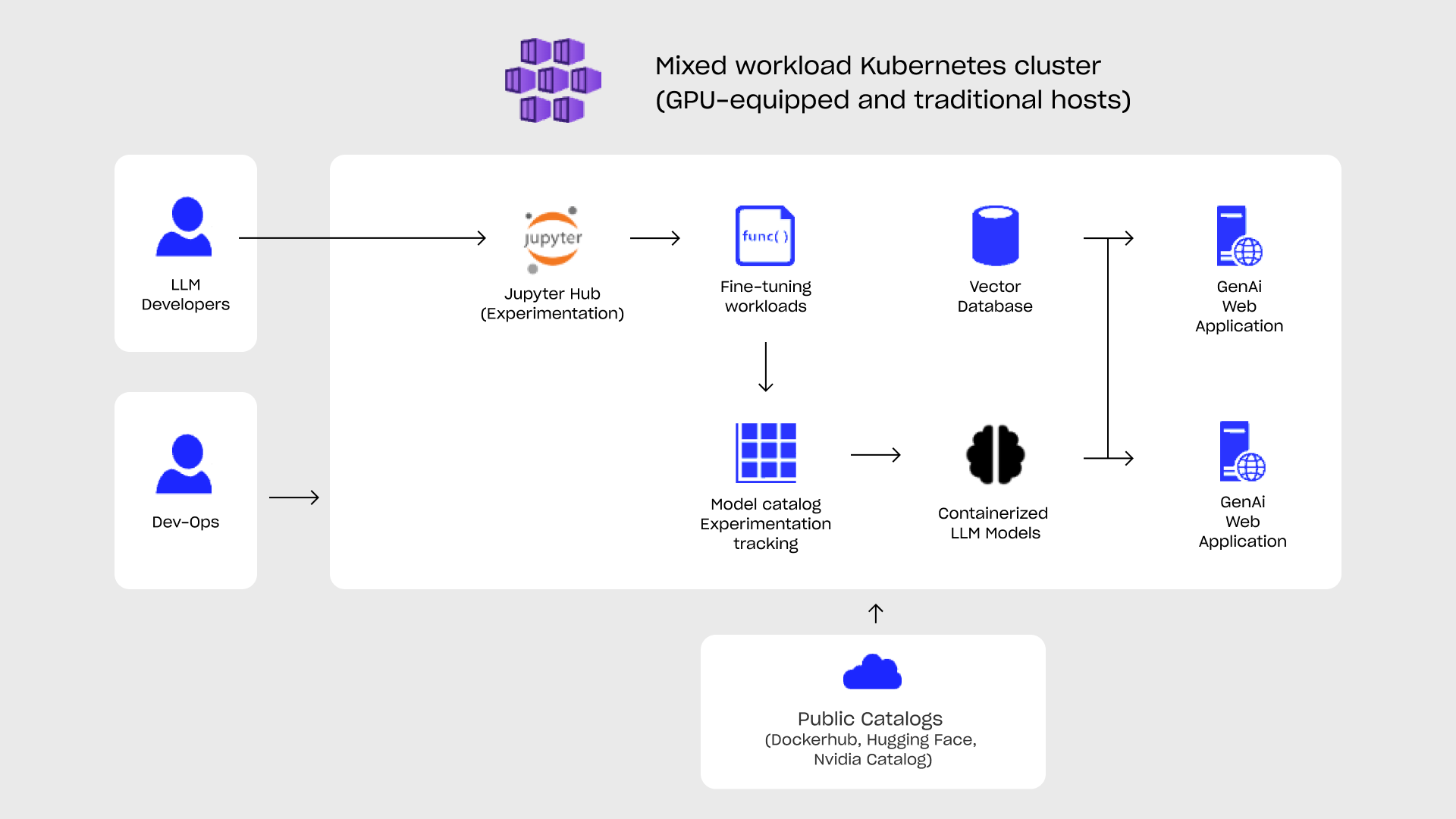
Fig. 3.: GenAI deployment architecture with Kubernetes on an on-premise cluster of heterogeneous nodes with and without GPU.
Kubernetes, the multi-host container orchestration framework already has the GPU scheduling support released in stable (v.1.26). This enables organizations to deploy AI and traditional workloads in a single cluster while chunking up the resources of a single host and enabling easy future extensions to the cluster.
LLM application suffers from the same difficulties as their non-AI counterparts thus the same measures should be taken when scaling for larger loads. From an application architecture perspective developers should start to slice their GenAI application into functional components to enable scalability on a function level. Vector databases should be extracted to their own pods and managed separately, as do the ingestion processing, experimentation workloads, etc.
To manage multiple inference deployments on different GPUs or servers, Kubernets’ built-in reverse proxy can be employed. This approach simplifies scaling by presenting a single LLM inference endpoint to the application, effectively masking the complexity routing while the reverse proxy distributes requests across multiple LLM models, enabling auto or manual scaling and letting inference performance be scaled seamlessly.
This setup enhances data retrieval speed and overall application responsiveness, providing a solid foundation for handling increased data loads. It also enables high-availability deployment processes like zero downtime maintenance, hot-hot redundancy and scaling which is indispensable for high-value applications with strict SLA.
Closing thoughts
The technology landscape for deploying Large Language Models (LLMs) on-premise is both ready and mature, offering robust solutions well-known from traditional deployments. The decision to move to an on-premise deployment should be guided by whether an organization can leverage the added benefits, such as low-latency, constant cost, and advanced fine-tuning capabilities that on-premise LLMs provide. The feasibility of a gradual infrastructure build-out allows organizations to start with simple, single-node deployments and scale out as their needs grow, minimizing initial risk and investment. This approach ensures a smooth transition and maximizes the benefits of AI investments, making it accessible for organizations of all sizes. With the right planning and incremental upgrades, the potential for innovation and growth in on-premise generative AI is immense, promising exciting opportunities for those willing to embrace this transformative technology.
In the next part, we’ll explore how the cost of an on-premise LLM deployment stacks up against hosted solutions and SaaS alternatives, and whether cost could be a key factor in the decision to move on-premise.
Appendix
[1] Turbocharging LLama2 by Perplexity AI: https://www.perplexity.ai/hub/blog/turbocharging-llama-2-70b-with-nvidia-h100
[2] ReAct: Synergizing Reasoning and Acting in Language Models https://arxiv.org/abs/2210.03629
[3] Run your AI inference applications on Cloud Run with NVIDIA GPUshttps://cloud.google.com/blog/products/application-development/run-your-ai-inference-applications-on-cloud-run-with-nvidia-gpus


