- Apr 28, 2023
- 7 minutes
Written By
-
 Andreas Blum
Andreas Blum
Introduction
Large language models (LLMs) like OpenAI’s ChatGPT, are transforming natural language processing (NLP) capabilities and certainly have the potential to unlock new business value, augment productivity and customer service across industries.
This article will address the changes LLMs bring from a managerial perspective. The objective for managers is to not understand the technological complexity but remain concerned with the corresponding strategic consequences; how are LLM advancements influencing AI strategies/projects, how to find and manage LLM use cases, what organisational changes are required, and what are new risks to monitor? In our next article we’ll unpack LLMs from a technical perspective, showing how to get started, technical risks and experimental use cases by combining technologies.
What are LLMs and how important are they for business?
LLM is a category within machine learning where models have natural language processing capabilities, allowing them to generate, classify, translate text (including code) and answer questions in a human-like manner. Their “large”-ness comes from the sheer mass in parameters these models can change autonomously whilst learning (i.e. GPT-2 had 1.5 billion values, with GPT-3 at a whopping 175 billion). To put this into perspective the average human brain has around 85 billion neurons.
ChatGPT took the world by storm becoming the fastest-growing consumer application in history. The unprecedented adoption rate largely came from its welcoming “chat-like” user interface, which made it super accessible for everyone. Its successful commercialisation has opened people’s eyes to what is possible with current generative AI models and started an implementation race, as companies rush to be the first to leverage ChatGPT in their industry.
Its ushering in a new era for AI-in-business because its the first AI advancement that has concrete applications out-of-the-box across all three business pillars; augment workforce productivity (e.g. generate, search & summarise documents), automate and improve quality of processes (e.g. customer service chatbots) and elevate tooling effectiveness (e.g. code generation/recommendation via Co-pilot). In a recent article, we explored OpenAI’s capabilities and use cases in content generation & search, lifting individual & team productivity, and customer-facing engagements within the Azure environment.
Implications of LLMs for AI management strategy
The introduction of next generation LLMs has consequences on two managerial fronts; the portfolio management of AI initiatives and AI as a cornerstone for competitive advantage.
Within portfolio management, there are two factors to consider; the cost-effectiveness of LLMs and the silver bullet fallacy.
Cost-effectiveness – As these models become “larger“, they achieve better performance out-of-the-box – that is, without being adapted to specific use cases – and it will only improve. Typically with model adaptation, costs accumulate via the required data collection, data annotation, model training, evaluation, monitoring and serving the model on dedicated hardware or cloud. However, with these ”large“ models, adaptation for many use cases (i.e. text generation, searching unstructured data) is unnecessary, and you can simply plug-and-play. From a managerial perspective, this changes how AI/ML initiatives are evaluated and implemented. Project proposals deemed too costly due to the collection of specialized labelled data may now be financially feasible. Initiatives with an extensive time horizon may now have a reasonable time-to-market. The introduction of LLMs calls for managers to reevaluate and reprioritise their AI initiatives/use cases. In many cases, LLMs, like OpenAI’s ChatGPT, can provide quick and impactful wins for the company.
Silver-bullet fallacy – LLMs like ChatGPT are a monumental advancement, opening up new avenues for use cases previously unattainable with existing natural language processing (NLP) solutions (e.g. allowing GPT-4 to use your computer to complete tasks). It’s tempting to think that ChatGPT is an equivalent or better substitute for all existing NLP solutions, especially because of its cutting-edge generative capabilities. However, for most “classical” NLP/NLU tasks such as sentiment analysis, translation, entity recognition, or classification, state-of-the-art task-specific API or models nearly always outperform ChatGPT. In other words, when considering AI initiatives for “traditional” language-related problems, we recommend not to preemptively eliminate narrow or task-specific NLP solutions from the evaluation.
“But hey, ChatGPT is not just about doing NLP tasks without learning, it’s clearly a game changer”. That is correct; the conversational ability greatly expands the types of possible tasks and is not something that can easily be replicated. LLMs, such as GPT-4 in particular, are going beyond traditional NLP tasks of understanding the text, like interpreting and responding in regional accents (e.g. British, southern, Irish etc.). In this respect, many NLP tasks can be considered a “solved” problem, and LLMs are inching closer towards becoming artificial general intelligence (AGI) across multiple fields, as shown in the paper.
Let’s shift gears and understand how ChatGPT’s introduction changes the notion of AI in competition.
AI for everyone – There are two key factors driving the democratisation of AI, from the supply and demand side, respectively; providers are offering increasingly accessible and affordable prices for AI solutions, whilst the blossoming no-code AI solutions market is expected to grow at roughly 30% CAGR for the next ten years (e.g. ChatGPT is no-code). With barriers to adoption practically vanishing, the gains of AI are no longer reserved for technically abled companies and/or have deep pockets. On its current path, generative AI tooling could become as usable and widespread as Google Search and will not provide differentiation. Competitive advantage will be championed by those who orchestrate and optimise the interactions between the four pillars of an AI-driven organisation; AI tools & models, data infrastructure & quality, users & use cases, and governance & compliance.

A sound approach to implementing LLM use cases
GPT-4 and other LLMs clearly reduce the cost and time-to-market for most new applications involving summarising or Q&A of unstructured data. They can be used to solve tasks that no previous model could do without massive effort. However, there are many use-cases where off-the-shelf LLMs don’t provide the most value and an in-house solution is preferable. It depends on the characteristics of the use case; degree of data modality, data security, compliance risk and model uniqueness.
Currently GPT-4 can process data that is either text, or image. If a use case requires different data types, like a chemical formula, then current off-the-shelf LLMs will not suffice. If the input data is sensitive, either for regulatory or competitive reasons, then consider an enterprise solutions provider (e.g. Azure OpenAI) or an on-premises solution. Model uniqueness refers to a use case that has the potential to generate a competitive advantage. In this case opting for an in-house model tuned to your organisations specifics could yield higher returns than an off-the-shelf model ever could.
Once the catalogue of use cases has been designated to either be outsourced or developed in-house, the next step is to minimise the projected costs of the catalogue. Reevaluate and re-designate the mix of outsource/in-house use cases by optimising the trade-off between model performance, cost of self-hosting & maintaining (i.e. LLMOps), in-house technical abilities, and legal risks.
What are the risks and strategies to mitigate?
1. Utilisation: With great power comes great responsibility. Employees uneducated on the risks have the potential to damage the competitiveness of their organisation. Case in point was a data leak incident that occurred at Samsung relatively soon after the release of ChatGPT. To prevent this companies should prioritise defining and clearly communicating their policy of use and providing the time to educate their people. This discourages employees from using it unofficially and concealing their use. As a secondary defence, integrate safeguards such as writing system prompts that constrain the responses and testing adversarial examples.
2. Data privacy: Using a cloud API means you send and store potentially sensitive data in the cloud. Opting for Azure OpenAI services can help to mitigate certain risks. Azure OpenAI is a service to use the OpenAI models and API from the Azure cloud. First, Azure OpenAI services does not share data externally, not even to OpenAI. By default queries are stored for 30 days, but you can request Azure to not store your requests. In case you fine-tune a model, it also stores your training data. To mitigate the risk ensure personal identifiable information and sensitive data are removed from the training data so that it is not leaked in the output of a generative AI model to a user who should not access it.
3. Copyright, IP and licensing: There is no clear regulation regarding the IP of content generated by AI. As LLMs are trained on copyrighted content, they can generate content similar or identical to copyrighted content. Finally, the license of certain LLMs does not allow to use them for commercial purposes
4. Reliability: Like any machine learning model, LLMs are not 100% reliable. It is highly recommended that any LLM output used for key business decisions is reviewed by a human. Their reliability is limited as they can confidently “hallucinate” information; it means the model rationalises a connection between two data points that are not at all related. Hallucinations can lead to made-up facts including names, numbers, etc, both related to the input (e.g. when summarizing an input) and not related to the input (e.g. answering on a public fact). While GPT-4 is less prone to hallucinate compared to ChatGPT-3.5, it remains a challenging issue. Methods to mitigate or detect hallucinations is to ask the LLM to cite sources and keep a human in the loop. Currently LLMs reliability is limited as they can confidently hallucinate information, they are not interpretable, and they don’t output a confidence score.
5. Reproducibility: LLMs – including OpenAI models – are non-deterministic, meaning calling the model twice with the same input often yield different outputs. This can cause issues for audit (lack of reproducibility), testing, or simply be disturbing for an end-user.
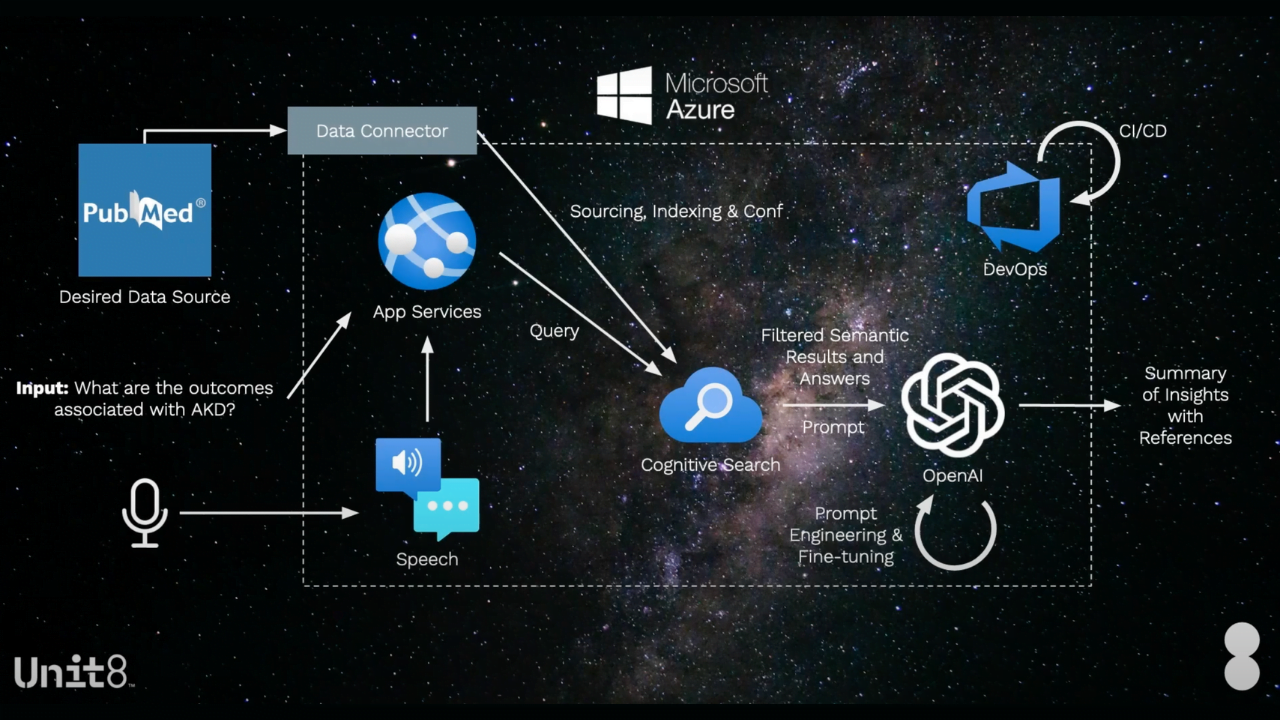
How Unit8 is helping companies to leverage LLM?
At Unit8, we’ve begun implementing simple and straightforward LLM use cases for our clients. For example, for a global pharmaceutical company we are programming ChatGPT to compare snippets of legal documents or to extract custom entities from them. For a European online retailer we are helping them summarise the opinion from online comments of their products. For a global private bank we’re setting up a personal assistant for their back-office operations.
If you’re curious to see how Unit8 can help you with realising GPT technology, we’ve recorded demos showcasing how it can be used to speed up the retrieval of information across vast amounts of unstructured data.