
- Jun 4, 2024
- 10 minutes
Written By
-
 Justyna Woźny
Justyna Woźny - Vincent Bardenhagen
- Ben Murphy
From the start, Unit8’s philosophy has been based on our commitment to responsibility beyond our professional duties and contributing positively to society.
As an integral part of our mission, we dedicate a portion of our time to causes aligned with our values, utilizing our expertise to make a meaningful impact.
We find that the best way to do this is to combine our skills with the mentioned values to create positive change for companies lacking easy access to such services.
Our expertise is leveraging advanced analytics to tackle complex challenges in partnership with our clients, and the contribution is offering our services without charge to non-profit organizations, such as Impact Initiatives.
Since the founding of Unit8 we have tried to improve in all aspects of our work. This includes the way we give back to the community. We have considered a variety of projects and set-ups and decided to partner with non-profit organizations that know the real needs in the development sector best. In this cooperation we figure out what data-driven solutions can assist our partner organization in their core business, rather than jumping on the latest technological trends. We plan before we act and develop a clear timeline and framework, and then we get to work. We followed this recipe in our project with IMPACT Initiatives and achieved great results.
Our Partnership with IMPACT Initiatives
Founded in 2010, IMPACT Initiatives is a Geneva-based NGO and a leading independent data provider in crisis situations. They aim to support various stakeholders in making more informed decisions in humanitarian, stabilization, and development contexts. Through its team of assessment, data, geospatial, and thematic specialists, it promotes the design of people-centred research and sets standards for collecting and analysing rigorous, high-quality data in complex environments.
The Business Challenge of IMPACT Initiatives
A primary focus for IMPACT Initiatives is to strengthen evidence-based humanitarian decision-making through efficient data collection, management, and analysis in complex and fragile settings like Syria and Haiti. One of the most significant challenges they face is ensuring high-quality data, particularly when data is collected by enumerators in hard-to-reach or insecure areas. Unfortunately, it is not uncommon for data to be misrepresented or incorrectly recorded, leading to potential inaccuracies in the survey results.
To mitigate this issue and recognise the importance of high-quality data, IMPACT has quality assurance processes, including heavy data cleaning processes both during and after data collection. This involves thorough reviews and, if necessary, the exclusion of portions of data to maintain integrity. The current approach presents two main challenges:
- The manual data cleaning process is time-consuming and requires significant effort to pinpoint problematic surveys.
- The conservative approach to data cleaning, while necessary to ensure quality, may result in a reduction of usable data.
The solution concept
The surveys are conducted using the KoboToolbox that is specifically designed for surveys on smartphones. The surveys come with an audit functionality that tracks the user’s actions while filling out the survey. This data opens an opportunity for a generalisable approach to identify surveys that were not filled out correctly.
A road to success
Proof of Concept (PoC):
There was a PoC done at the Hack4Good initiative at ETH under supervision of Vincent (also author of this article), that lacked some rigorous capability testing and a scalable implementation, but showed promising capabilities.
The PoC contained some important steps on the road to success:
- Get the experts involved, who have dealt with these types of surveys for a long time. Discuss with them how suspicious behavior could reflect in the log data.
- Translate these behaviors into algorithmic representations and implement those to derive features.
- Evaluate the distribution of these features individually and validate that the EDA fits to the conceptual ideas behind the features
- Train an Isolation forest to score the different samples on their “ease to isolate” which can be used as an anomaly detection.
Our Project
Our project had two main goals:
- Make the codebase production ready by introducing kedro for best practices in data pipelines, connecting to the kobo api and make the code easily adaptable for future surveys
- Introduce metrics to evaluate the quality and robustness of the anomaly detection approach
Production ready
To go from PoC to a production ready set-up that can realize the full potential we were facing a couple of challenges.
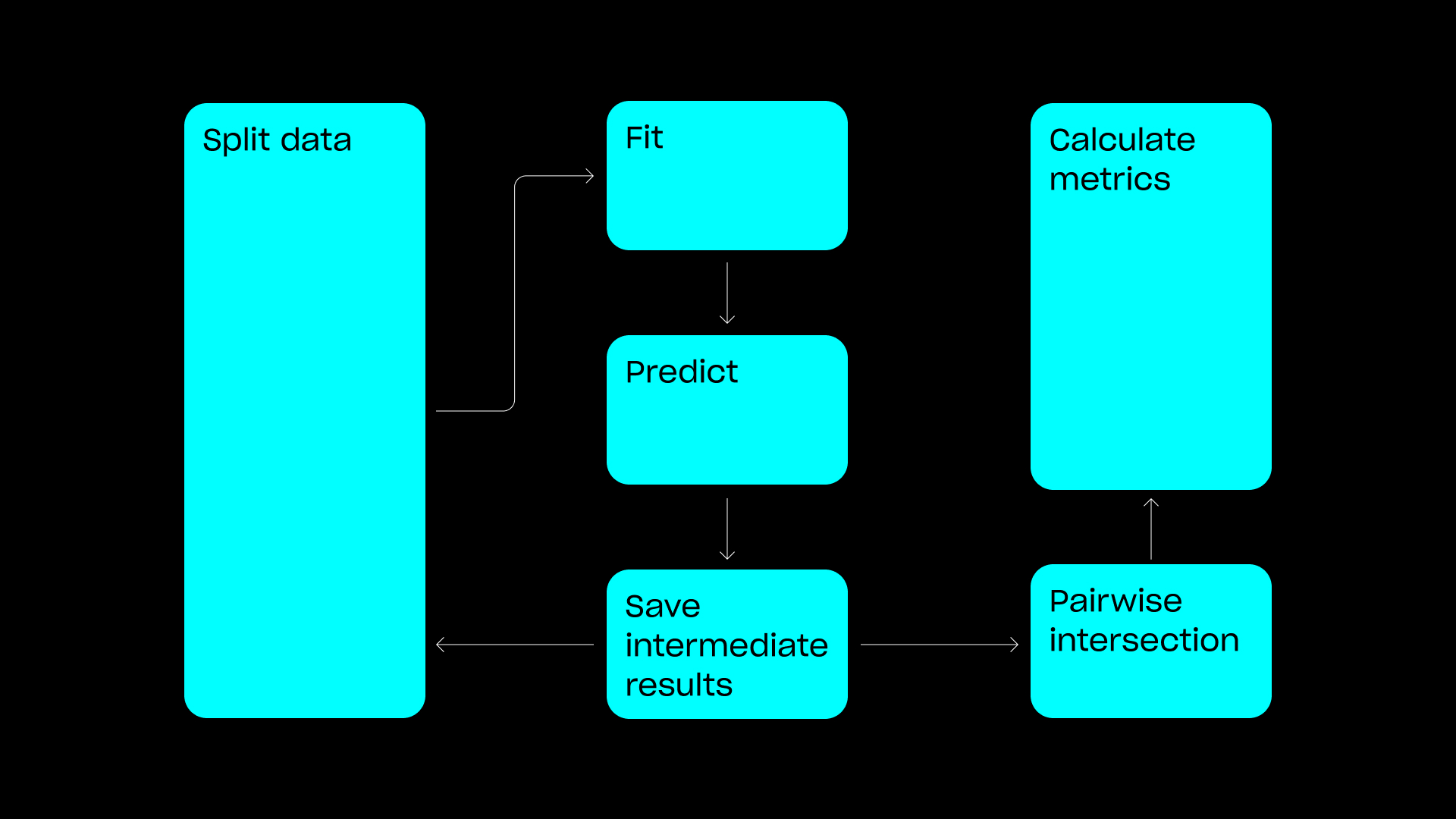
Impact Initiatives traditionally have focused on statistical analysis rather than data science software projects and thus do not have an internal standard we could follow. Hence, we suggested using https://kedro.org/ an open source project that first and foremost provides a well documented standard for setting up and developing data science projects. It has a variety of additional features from pipeline visualization to experiment tracking that came in handy. Furthermore, it abstracts away the data loading process from the analysis and allows us to connect to the kobo api and support locally downloaded files.
We transferred the code implemented by the students into the kedro framework providing a single file to change to run the survey on a new dataset. This file is to enter the different column naming conventions of surveys, adding the credentials to access the api or connect to the download folder with the files.
The outputs are written to excel files in two structures. One with the information on the individual surveys and which ones were filled out with the most anomalous audit information logged. Additionally, we applied “Assist-Based Weighting Schema (AWS)” to derive interpretability of the results returning the features contributing most to the anomalous rating with the explanation of what behavior they relate to. The other one is structured by the enumerators to see which enumerator shows the most unusual behavior filling out the survey.
For data scientists wanting to further improve and monitor the solution we create few visualizations and reporting metrics to validate the algorithm is behaving as expected.
Validation Metrics
The biggest challenge was that there was no ground truth data for anomalous surveys. While cleaning and deletion logs for historical surveys are available, they are likely incomplete and/or include non-erroneous surveys as based on a manual process. We had to develop metrics that could give us insights into how the algorithm would behave in a realistic scenario.
For this first we had to establish the way the tool should be used in the production. We converged to using the algorithm as a ranking approach rather than a binary labeler, as the survey supervision team is regularly in touch with enumerators in the field. The algorithm allows them to make the most efficient use of their time by indicating which surveys or enumerators should be contacted to check for any problems in data collection.
The workflow was defined as follows:
- A new survey is launched and following training and piloting, enumerators go out in the field and collect data.
- On a daily basis, filled surveys are uploaded to the kobo server and can be accessed by the survey supervision team.
- Once a sufficient number of surveys are filled out the algorithm starts to run on a daily basis.
- The top ‘anomalous’ rated surveys are checked by the survey supervision team, either by looking at the entered data or by contacting the enumerators.
- If no sufficient explanation for the anomaly detected in the algorithm can be given by the enumerator, a faulty survey has to be assumed.
Based on the insights into the field usage and the impossibility to generate ground truth labels we derived a validation procedure.
We wanted to ensure that the predictions of anomalies are robust and not sensitive to the surveys that were collected. The assumption is that if all audit files are very similar the algorithm will randomly select anomalies and small changes in the composition of the training data set will strongly impact the results. However, if there are outliers that have a changed underlying data distribution (clicked through the survey instead of conducting an interview to get the data) these should consistently be picked up even if a different subsample of data is used for training.
The validation procedure we implemented is sampling multiple subsets of the available data and running the feature generation and anomaly detection algorithm on this set. We then create intersection sets between these different training subsets and compute different metrics on these, that should reflect given both training data sets, would they have been selected for human validation?
The metrics we use to compare the different rankings are root mean squared error, spearman correlation and kendall rank correlation. Furthermore, we have implemented rank and normalized rank differences that show on average how many places the outcomes differ.
| mean across 45 sample intersections | |
| Intersection average size | 600 audits |
| RMSE | 0.0123 (Score of IsolationForest range from -1 to 1) |
| Spearmanr | 0.952 |
| Kendalltau | 0.815 |
| Rank difference | 39.556 |
| Normalized rank difference |
0.066 |
The metrics indicate that the predictions made by the Isolation Forest Model are consistent across subsets thus showing low sample dependency and high robustness.
The validation results as well as the preparation of the code now allow IMPACT to pilot this solution during live data collection exercises. During this pilot, IMPACT is advised to store the results of the manual validations of the algorithm, including feedback from enumerators. The pilot will be done this summer (May to September 2024) with data collected in Syria and the team based in Jordan supervising the effort.
Conclusion
Before the implementation phase, we took our time collecting the requirements, understanding the usage goal, and ensuring that the capacity of the teams of Unit8 and IMPACT were aligned, when implementation starts. The implementation was done in the short time of 6 weeks by Ben Murphy under the supervision of Vincent Barenhagen. We kept our focus on the most important aspects to get a solution ready that can be used by IMPACT.
This approach has led us to great results and very happy stakeholders from IMPACT:
“Unit8 has been instrumental in laying the groundwork for our upcoming pilot aimed at automating anomaly detection in survey data. Their proactive collaboration with our team has ensured a thorough understanding of our needs and objectives, and with their tailored solution, we hope to be able to significantly improve our ability to identify outliers and anomalies in data collection, ultimately bolstering the reliability and integrity of our findings.
We are grateful to Unit8 and look forward to our continued partnership.
While we have to wait for the first actual survey to be done with this tool to draw a final conclusion, we can already say that good planning and focused execution have led to great results.”
If you are in a similar situation and want to give back to the community with your companies tech or consulting expertise here are a few of our most important learnings on setting up such a cooperation:
- Treat non-profit organizations with the same dedication and professionalism as any other client.
- Clearly define the scope of the project. Avoid overly ambitious goals and break the project down into manageable tasks with realistic effort estimations.
- Establish clear responsibilities with your non-profit partner. Mutual accountability can be challenging when financial transactions are absent. Address this by formalizing agreements, such as a memorandum of understanding, before commencing the project.
- Gain a deep understanding of the non-profit’s operations. Instead of pushing advanced technology for its own sake, focus on identifying genuine issues and addressing them with the most suitable technology.
- Be patient and flexible. Non-profits often operate with limited resources, and waiting for the right moment to start can be crucial for the project’s success.




