
- Mar 26, 2024
- 8 minutes
If you have just recently heard the term “vector database” for the first time and want to understand how they work, you’ve come to the right place.
The increasing interest towards vector databases is closely related to the release of ChatGPT. As we now realize the impressive capabilities of Large Language Models (LLMs), vector databases can enhance these models even further, offering a more accurate information retrieval throught RAG architecture. Allowing a better and more effective way of retrieving relevant information, vector databases are a key component in unlocking the full potential of LLMs.
This article will illustrate how your organisation can benefit from vector databases by describing existing applications. After covering those applications, the article will walk you through the core concepts of a vector database (such as vector embeddings and vector indexing), and clarify how they work.
Vector database use cases
Vector databases represent a cutting-edge solution for businesses dealing with massive datasets characterized by the efficient storage and processing of data. The importance of vector databases lies in their ability to support diverse applications, enabling quick retrieval and similarity searches within vast datasets. Those datasets may encompass various data types, including text, numerical values, PDF documents, images, and others. The article will provide definitions and detailed explanations later on. With vector databases, organizations can enhance the speed and accuracy of queries, ultimately facilitating more robust and efficient data-driven decision-making processes.
As a result, vector databases have recently gained importance in various sectors, revolutionizing the way data is stored, processed, and analyzed. These databases support a wide range of applications in fields such as technology, science, and industry. Here are a few use cases illustrating how you can leverage vector databases for your business:
-
ChatGPT-like FAQ through information retrieval:
When receiving a user’s query, any ChatGPT-like system needs to find documents, sentences, or words that are similar in meaning to the request. By comparing the user input to information that is already stored, the database can quickly identify and retrieve content that closely matches the query’s semantic content. Hence, vector databases play a crucial role in improving the speed and effectiveness of searching for relevant information. Overall, any use case discussed in “The top four most requested GenAI Use Cases“ article (by Unit8) will be enhanced by vector databases.
-
Fraud detection:
In the banking industry, one must verify that the received transaction is not fraudulent. Here again, the retrieval abilities of vector databases can be leveraged. By storing all activities encountered until now, a vector database can quickly check if the received transaction is similar to an honest or fraudulent activity. The similarity-search capabilities of vector databases allow financial institutions to have a faster, more accurate, and more cost-effective approach compared to human labor.
-
Product recommendation/ Personalized advertising:
Any E-commerce website seeks to predict and show the items that a customer would like to purchase. A common approach is to suggest products similar to one that the customer likes. Again, vector databases can be leveraged by storing all products proposed by the vendor. When a customer is searching for an item, the database can be used to give personalized recommendations by retrieving similar objects to the one your customer is looking for. Proposing adequate recommendations for a business drives sales and enhances the user experience, leading to increased engagement and loyalty of the customer base.
The essence of Vector Database
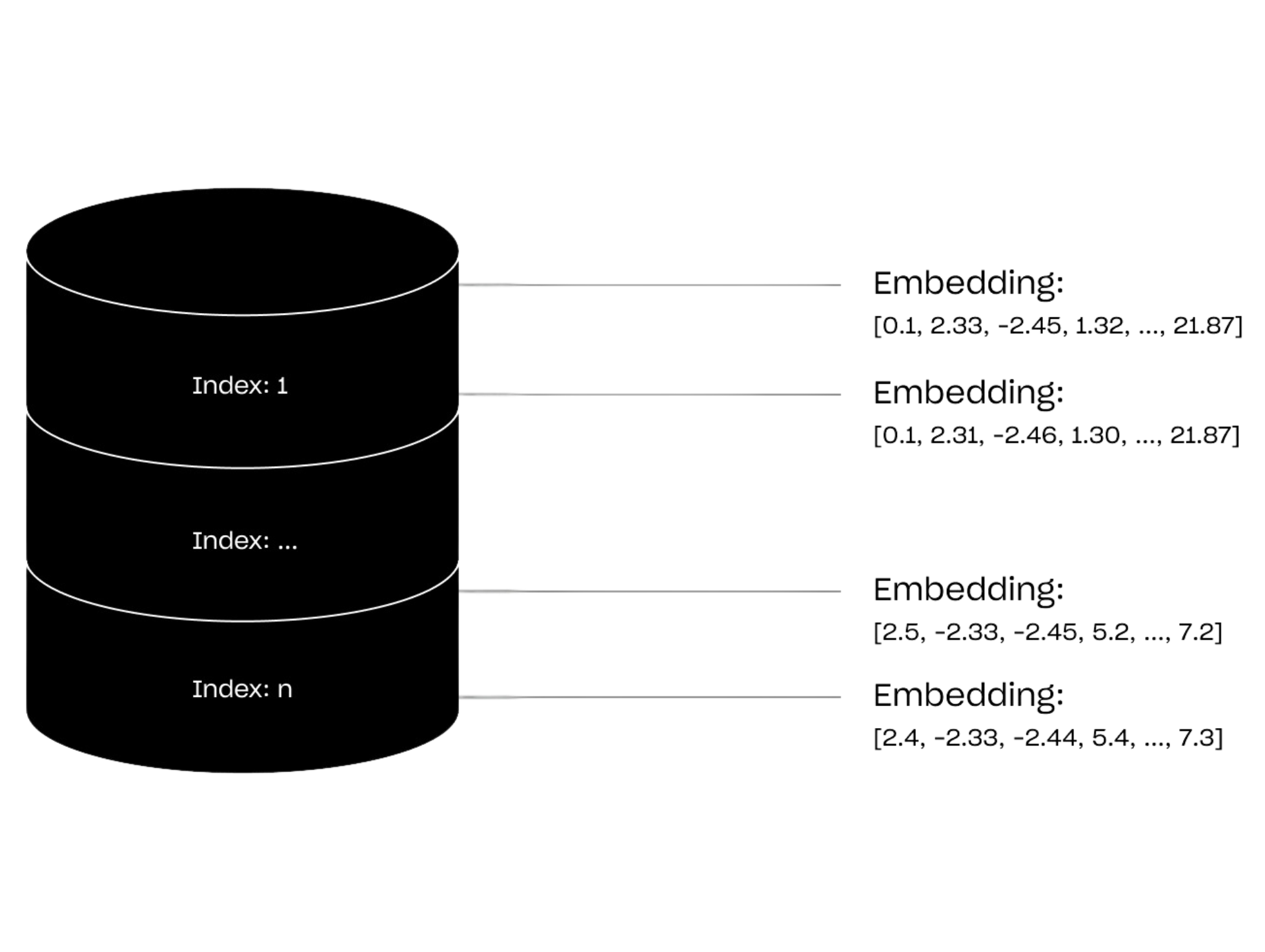
Like standard databases, vector databases are used to store information. However, the key distinction lies in what these databases store. Standard databases store the object itself so that it can be retrieved later, whereas vector databases will keep a list of features (called vectors) of the object but not the object itself.
To illustrate this concept, consider a scenario where you want to catalogue every book in a library within a database. On one hand, a standard database would store every book by saving the content of the book itself. On the other hand, a vector database would first convert the book into a vector by extracting features before storing it. It is important to note that the whole book is not stored in a vector database but only a representation consisting of those extracted features. The features collected could be the name of the book, the author, the genre, the length of the book, etc…
Assuming we are keeping only three features, this representation could be illustrated as shown below. Each point represents an object in the database.
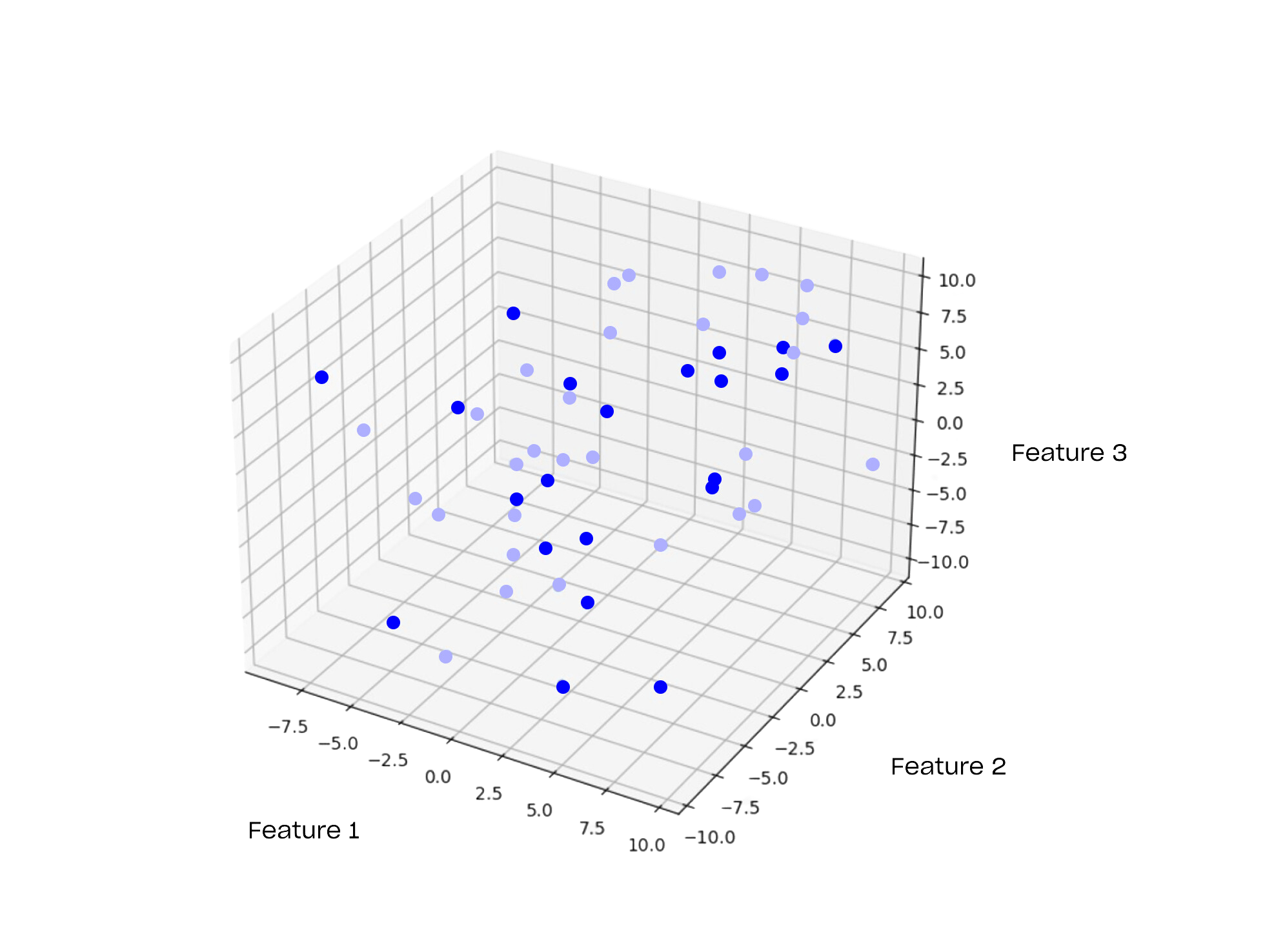
Visual representation of embeddings
Vector Embedding
A vector embedding serves as a computer-readable representation of an object, document, sentence, or word. If you ask yourself what it looks like, it takes the form of a fixed-length list of numerical values:
For example, the embedding of the word car could be [0.1, 2.33, -2.45, 1.32, …, 21.87]
To generate an embedding, various machine learning models take data as input and produce an embedding resembling the example above. The features used by these models to create the vector of numbers are often not explicitly clear, making the interpretation of these numbers challenging.
One particularity of those models is that they capture the semantic similarity of inputs. In other words, inputs with similar meanings will yield similar embeddings:
Keeping the previous example, the embedding of the word car could be [0.1, 2.33, -2.45, 1.32, …, 21.87]
the embedding of the word bus could be [0.1, 2.31, -2.46, 1.30, …, 21.87]
Keeping our initial visualisation, this would imply:
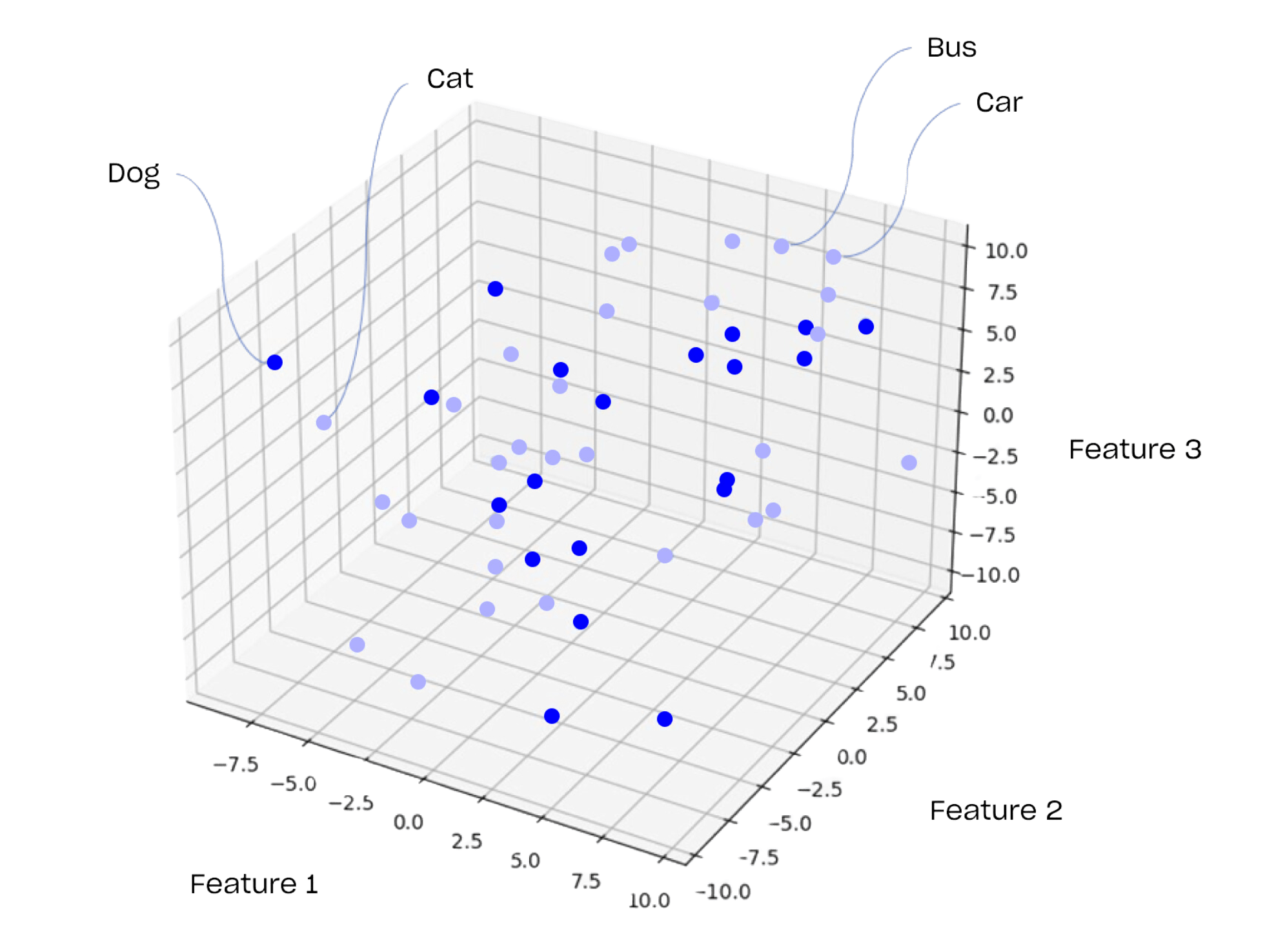
Visual representation of embedding with the corresponding meaning
In summary, a vector embedding is a fixed-length list of numbers that captures the semantic meaning of a document or text
Vector Indexing
In our context, indexing refers to the way we store our vectors in the database.
To grasp the concept, let’s consider the scenario of searching for a book similar to one you enjoyed in a library. If all the books are put on the library shelf without any particular order, you’d find yourself searching through each book one by one in a time-consuming and inefficient manner. To tackle this problem, most libraries employ a system known as the Dewey Decimal Classification, where every book is assigned to a number based on its topic. For example, all bibliographies are designated with the number 010, while encyclopaedias are labeled with 030, and so on. The library shelves are then organised based on those classification numbers. When searching for a book, the first step is to navigate to the section housing books with the relevant classification number. In this case, we say that books are indexed using their topic (ie. the classification number). This is helpful if you want to find a book that is on the same topic.

Using a classification, we are able to significantly speed up our search.
Now, we have embeddings stored in a vector database instead of books in a standard database. Revisiting our previous example, our objective is to identify embeddings that are similar to the embedding of the queried book. If the embeddings are not organized or indexed, the system would need to compare every embedding in the database against our reference embedding to determine the closest matches. While this brute-force approach does guarantee the discovery of the nearest embedding, it’s highly inefficient. Similarly to Dewey Decimal Classification, we can use indexing to make embedding retrieval faster.
Following the same approach as the Dewey Decimal Classification, indexing in vector databases is created by assigning to each embedding a value using a predefined function. These functions typically preserve the locality property of the embeddings, meaning that similar embeddings will have the same output when passed through the function. Vector databases use these outputs to index the different vector embedding. If you are interested in having more details about such functions, you can refer to Locality Sensitive Hashing (LSH) or Inverted File Indexes (IVF).
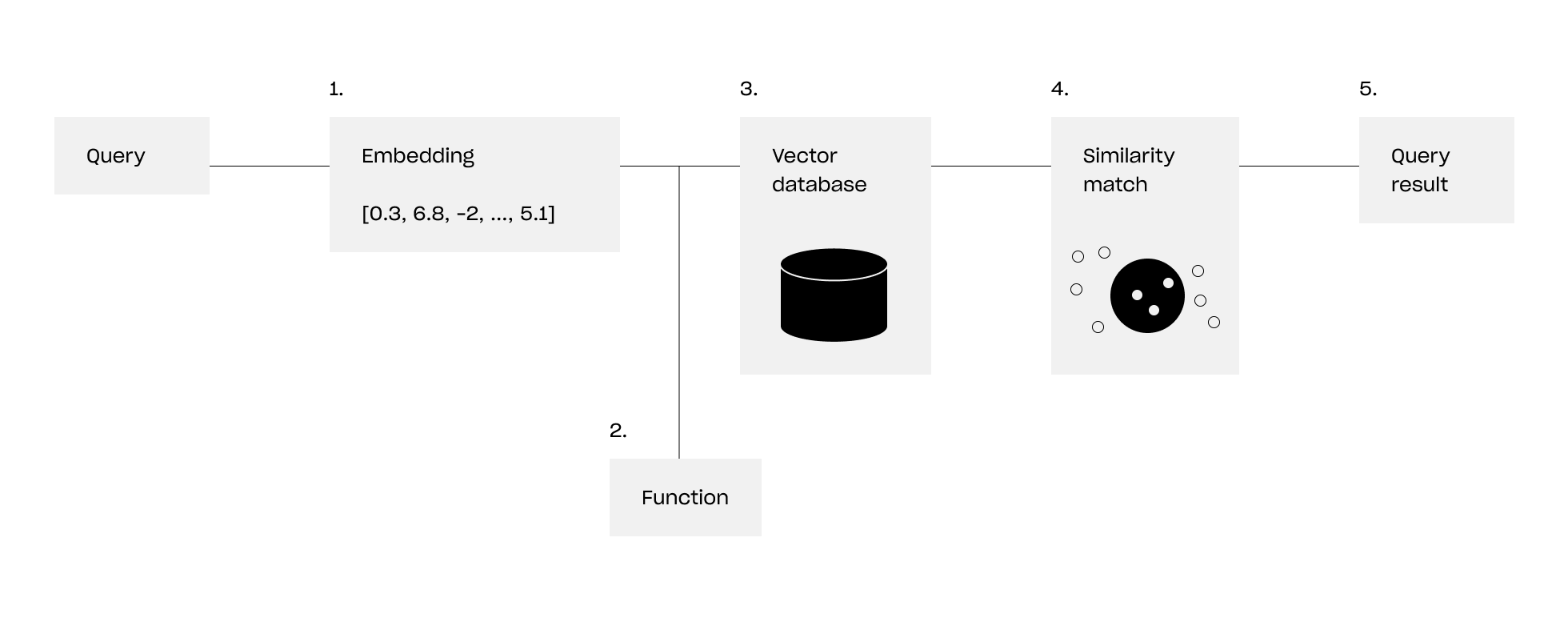
How does a Vector Database work for semantic search
Before conducting searches, there is a crucial preparatory step in the creation of the vector database. Assume you have a collection of books that you want to store in your vector database library. The database will be created by iterating over every book, generating the associated embedding, applying the function, and storing the function’s outcome along with the embedding. As explained in the previous section, this indexing approach relies on the function’s outcome, keeping semantically similar documents in close proximity.
With the database, we are capable of performing semantic searches. Here’s the procedure:
- Generate an embedding for the document you intend to search.
- Apply the function employed during database construction to the embedding generated in step 1, producing an output.
- Utilize this output to access the database and retrieve all documents associated with the same function output.
- For each document retrieved, apply a similarity function to pinpoint the closest matches.
- Retrieve the documents linked to these closest embeddings.
Due to the locality of the function used, we have the guarantee that only the results that are similar to the initial query are retrieved. Knowing these steps, you can now understand the power of vector databases enabling quick retrieval and similarity searches that can be used for FAQ, fraud detection and recommendation systems.
Conclusion
In conclusion, vector databases have impacted a multitude of sectors, from data science and healthcare to finance. The prospect of retrieving and analyzing data within vast datasets has captured the attention of data scientists, analysts, and decision-makers. As businesses continue to struggle with the increasing size of datasets, the capabilities offered by vector databases are indispensable for staying ahead in the rapidly evolving landscape of modern data analytics. Notably, OpenAI’s retrieval feature leverages this technology, allowing it to enrich its assistant with uploaded files. Companies like Palantir incorporate this technology into Foundry, showcasing its relevance in mission-critical platforms. Moreover, the market is witnessing a surge of new entrants offering vector databases, indicating the broadening adoption of this technology across various sectors. Among those new companies, we note Pinecone, Milvus, Chroma and Qdrant.
As we move forward, it’s clear that vector databases will remain a cornerstone of innovation and discovery. They empower us to make sense of the ever-expanding universe of data, turning it into valuable insights, breakthroughs, and solutions that benefit society at large. The journey of vector databases is far from over; it’s an exciting path with endless possibilities, and their influence on the way we manage, understand, and utilize data will continue expanding.


